Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience
此论文为 Facebook 发表在 FAST’21 上的论文,回顾了 RocksDB 在过去 8 年的演进中设计上核心关注点的变化及相应的优化措施,以及在性能,功能,易用性上所做的探索工作;此外还总结了将 RocksDB 应用于大规模分布式系统及系统错误处理上需要考虑的一些问题及经验教训。论文中没有论述具体的技术细节,更多的是从宏观的面上讨论了核心设计思想及工程实现上的各种权衡。
下面就来看下此论文具体讲了些什么,引用部分为我自己的笔记。
1 引言
RocksDB 是 Facebook 基于 Google 的 LevelDB 于 2012 年开发的一款高性能 KV 存储引擎,在设计之初 RocksDB 就是针对 SSD 来进行设计及优化的,且 RocksDB 的定位一直都很清晰——只做一个核心存储引擎而不是完整的应用,作为一个嵌入式的库集成到更大的系统中去。
RocksDB 是高度可定制的,因此它作为一个核心 KV 存储引擎能适应各种工作负载,用户可以根据自己的需要对它进行针对性调优,如为读性能优化,为写性能优化,为空间使用率优化,或它们之间的某个平衡点。正是因为如此灵活的可配置性,RocksDB 可以作为很多不同数据库的存储引擎使用,如 MySQL,CockroachDB,MongoDB,TiDB 等,也可以满足流式计算(Stream processing),日志服务(Logging/queuing services),索引服务(Index services),缓存服务(Caching on SSD)等多种特性完全不同的业务需求。这些不同业务场景特性总结如下:
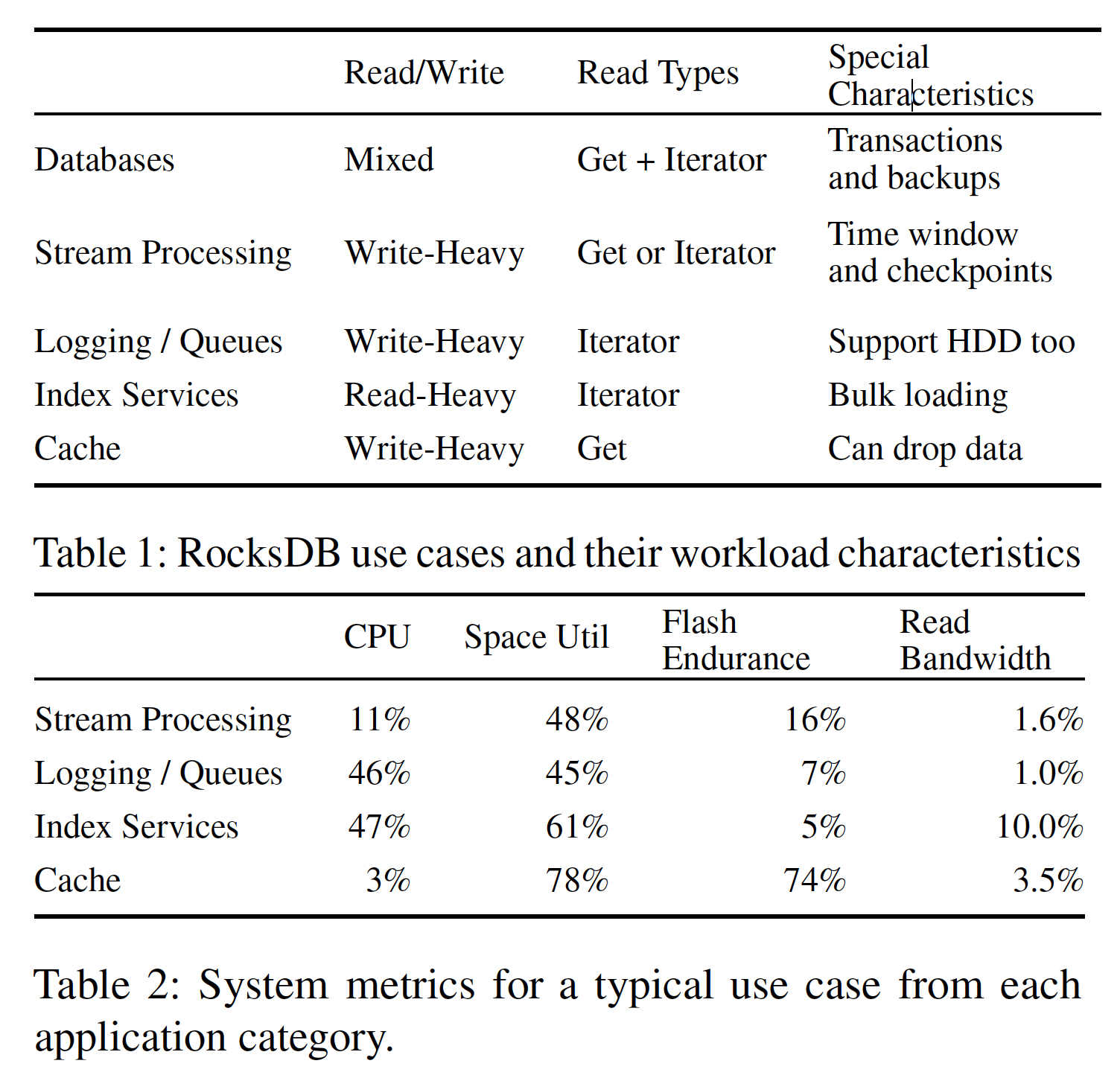
这么多不同应用共用一个相同的存储引擎与每个应用都去搭一套自己的存储子系统相比有很多优势:
- 无论是多简单的存储相关应用都要处理数据损坏,异常恢复,文件系统错误处理等问题,一个统一的存储引擎可以把这些都处理了,避免重复造轮子;
- 由于使用了同一套存储引擎,不同系统间可以共用一套统一的基础设施,如一致的监控系统,运维工具,调试工具等;
- 由于底层都是一样的,各种调试经验等在不同应用间都是可以复用的。
文中说这些基本就是用一个统一轮子的好处了,其实对于个人来说还有些其他额外好处,由于不同公司不同 Team 都选用了同样的底层引擎,人员流动就会变得更方便了:)
引言最后照例介绍了下文章结构:
- 第 2 章主要介绍了 RocksDB 之所以选择 LSM-tree 作为其核心数据结构的考虑。作者认为 LSM-tree 至今都很好,选用 LSM-tree 也是 RocksDB 能适应各种不同工作负载的关键所在;
- 第 3 章主要介绍了 RosksDB 的核心优化目标的变化,由最小化写放大到最小化空间放大;由性能优化到效率优化;
- 第 4 章主要介绍了使用 RocksDB 搭建大规模分布式系统时的一些经验教训;
- 第 5 章主要介绍了 RocksDB 在错误处理方面的一些考虑;
- 第 6 章主要介绍了 RocksDB 对于 KV 接口演化的一些思考;
- 第 7,8,9 章则分别是相关工作介绍,未来发展方向展望及结论。
2 背景
2.1 基于 SSD 的嵌入式存储引擎
RocksDB 设计之初就是为 SSD 及现代硬件优化的。SSD 的 IOPS 及读写带宽都大幅优于传统机械硬盘,不过其寿命有限,且写入性能会由于擦除而恶化,因此设计一款针对 SSD 的嵌入式 KV 存储引擎就变得更有必要了,这就是 RocksDB 的设计初衷——设计一款极具灵活性可用于各类应用的,使用本地 SSD 并为其优化的 KV 存储引擎。
2.2 RocksDB 架构
RosksDB 的核心数据结构是 LSM-tree,其基本结构如下:
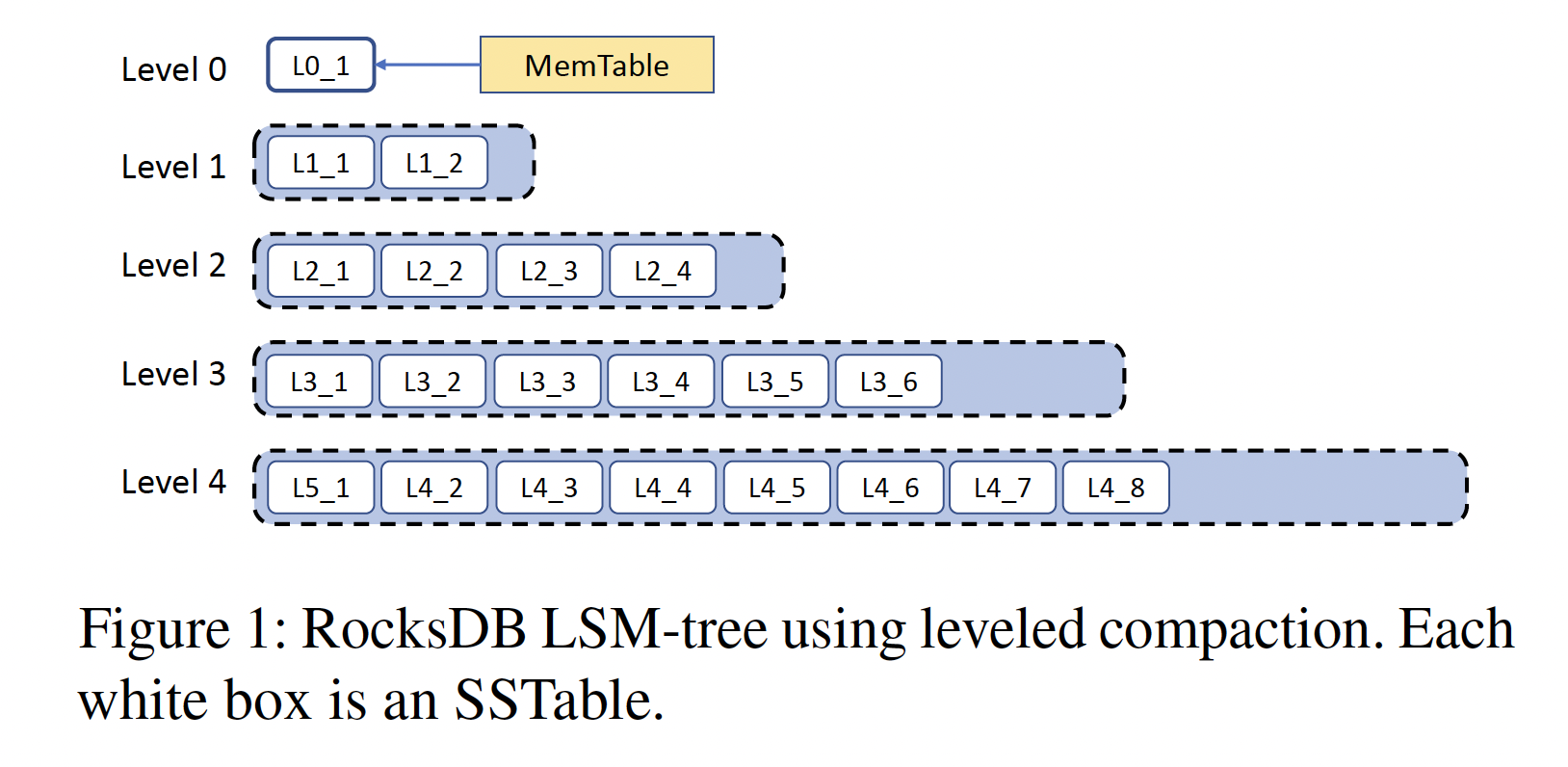
几种基本操作的流程简述如下:
写入(Writes)
先写 Memtable 及 WAL 文件(Write Ahead Log),Memtable 通常使用跳表(Skip List)作为其数据结构。Memtable 写满后转换为不可变的 Memtable(immutable Memtable),并同时生成一个新的 Memtable 供写入;随后 immutable Memtable 会被写入到磁盘上变成 SST 文件(Sorted String Table)。
压缩(Compaction)
Compaction 有多种不同算法,RocksDB 最古老的 Compaction 算法是源于 LevelDB 的 Leveled compaction。其基本原理如上图所示,Memtable dump 生成的 SST 文件位于 Level-0,当某个 Level 中所有 SST 大小超过阈值后选择其中的一部分文件 Merge 到下一个 Level 中。除 Level-0 外,其他 Level 内不同 SST 文件间 key 的范围没有重合。
读取(Reads)
读取时从小到大遍历所有 Level,直到读到为止。可使用布隆过滤器(Bloom filters)来避免不需要的 IO。Scan 时需要扫描所有 Level。
RocksDB 支持多种不同的 Compaction 算法:
- Leveled compaction。源自 LevelDB,上文已经介绍了其原理,每一层的阈值是指数形式增加的。
- Tiered compaction,RocksDB 中又叫 Universal Compaction,类似 Apache Cassandra 或 Hbase 中使用的方法,简单的把多个小的 SSTable 合并成一个大的 SSTable。
- FIFO compaction,达到大小限制后直接把最老的 SSTable 丢掉,这种策略只适用于一些纯内存的 Cache 应用等。
Tiered compaction 与 Leveled compaction 的核心区别在于每个 Level 中不同 SSTable 间 Key 的范围是否有重叠(overlap),leveled compaction 策略下同一 Level 内 SSTable 间 Key 是不会有重叠的,因此读的时候只会读一个 SSTable,IO 放大是可控的。Tiered compaction 则没有此性质,不同 SSTable 间 Key 范围是有重叠的。这两种 compation 策略的选择其实也是读放大与写放大间的权衡。
可以进一步参考下此文:LSM Tree的Leveling 和 Tiering Compaction
可以使用多种不同的 Compaction 策略使得 RocksDB 可以适用于广泛的应用场景,通过配置 RocksDB 可以变成为读优化,为写优化或极度为写优化(用于 Cache 等应用中)。不同的配置其实是读写放大间的平衡问题,一些实际的测试结果如下:
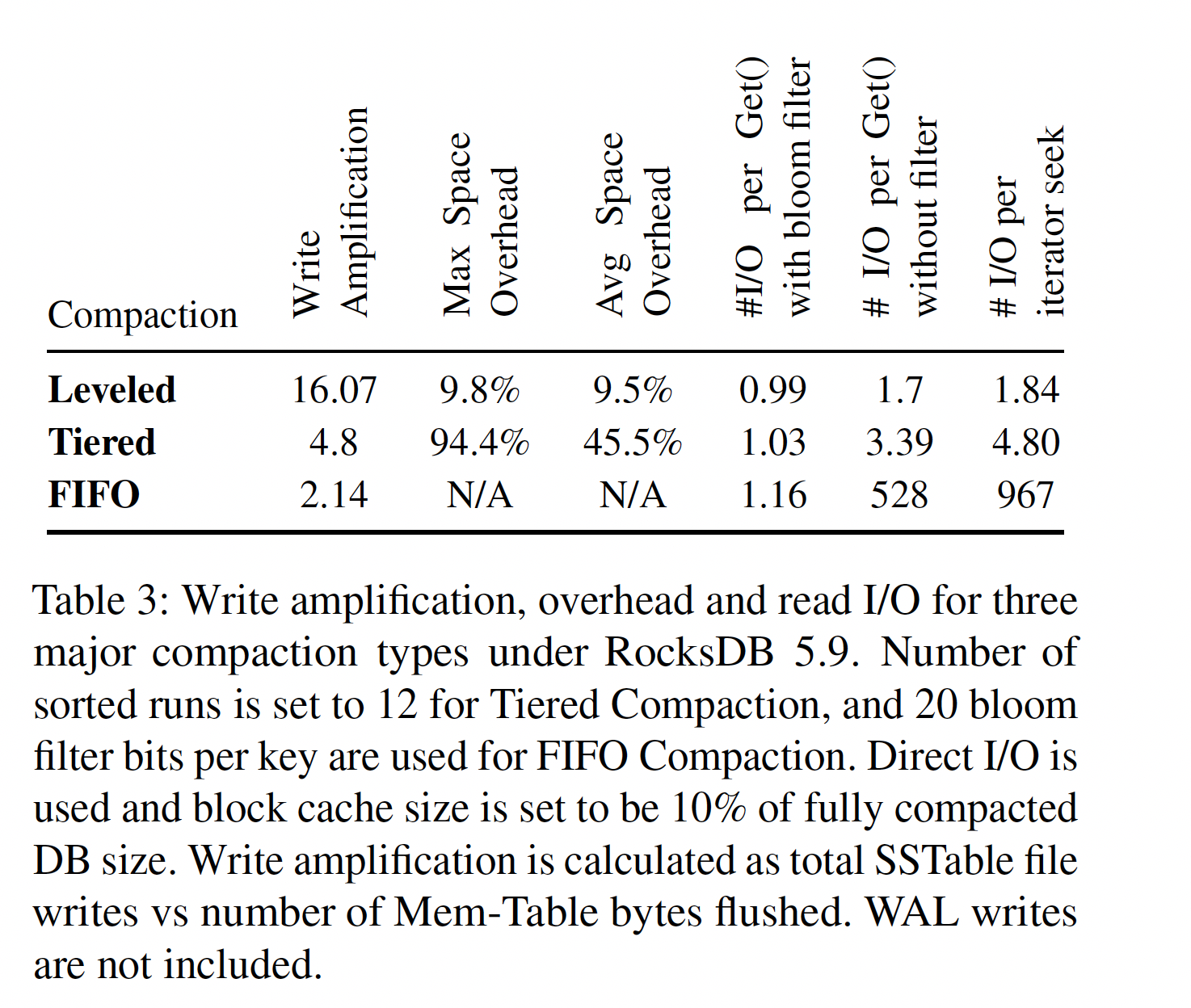
3 资源优化目标的演进
RocksDB 的优化目标最初是减少写放大,之后过渡到减少空间放大,目前重点则是优化 CPU 使用率。
写放大
这是刚开始开发 RocksDB 时的重点优化目标,一个重要原因是为了减少 SSD 的写入量以延长其寿命,这对某些写入很多的应用来说至今仍然是首要优化目标。
Leveled compaction 的写放大系数一般在 10~30 左右,这在大部分情况下是优于 B-tree 的,与 MySQL 中使用的 InnoDB 引擎相比,RocksDB 的写数量仅为其的 5% 左右。然而对于某些写入量很大的应用来说,10~30 的写放大系数还是太大了,所以 RocksDB 引入了 Tiered compaction,其放大倍数通常在 4~10 左右。
空间放大
在经过若干年开发后,RocksDB 的开发者们观察到对于绝大多数应用来说,空间使用率比写放大要重要得多,此时 SSD 的寿命和写入开销都不是系统的瓶颈所在。实际上由于 SSD 的性能越来越好,基本没有应用能用满本地 SSD,因此 RocksDB 开发者们将其优化重心迁移到了提高磁盘空间使用率上。
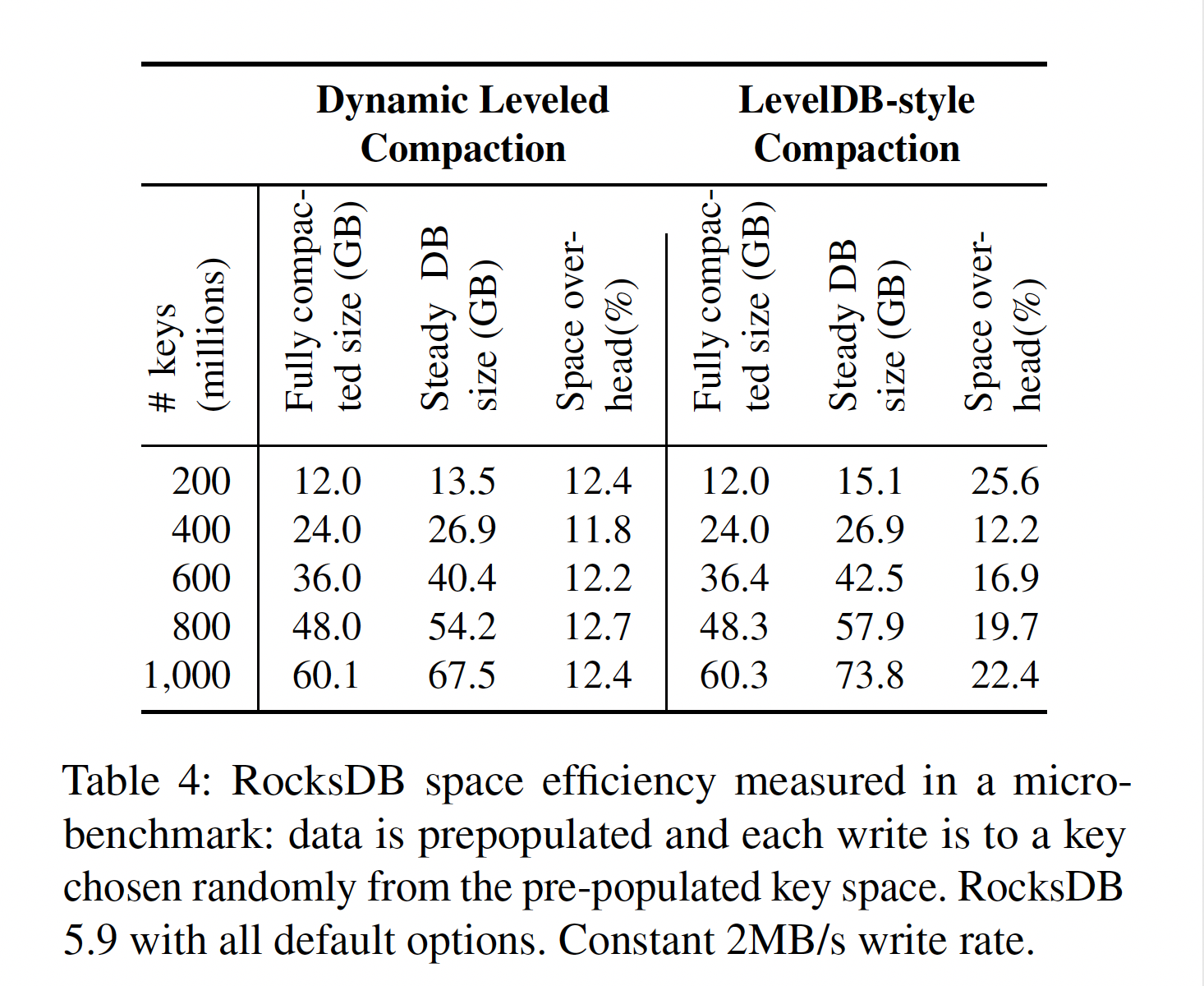
RocksDB 开发者们引入了所谓的 Dynamic Leveled Compaction 策略,此策略下,每一层的大小是根据最后一层的大小来动态调整的。
Tiered compaction 的空间放大和 Level compaction 根本没法比,极端情况下需要预留一半空间才能顺利进行完整的 compaction,因此这里就直接不讨论了。
Dynamic Leveled Compaction 的具体介绍可参考:
Dynamic Level Size for Level-Based Compaction
核心思想就是让稳态情况下更多的做一些 compaction。
此策略的效果如下:
CPU 使用率
随着 SSD 的速度越来越快,一种普遍的担心是,系统的瓶颈会不会由磁盘 IO 转移到 CPU 上呢?然而作者认为无需担心此问题,原因如下:
- 真实场景中,只有极少数应用会受限于 SSD 能提供的 IOPS,绝大部分应用是受限于 SSD 的存储空间;
- 目前高端服务器 CPU 有足够多的计算资源来满足一块高端 SSD 的需求,当然如果一台机器上有多块 SSD,则 CPU 是有可能会成为瓶颈的,然而作者认为这是系统配置问题,完全可以通过调整 CPU 和 SSD 配比来解决此问题……
- 就算某些应用 CPU 真成瓶颈了,这意味着此时存在大量 SSD 写入,这也意味着这块 SSD 命不久矣……
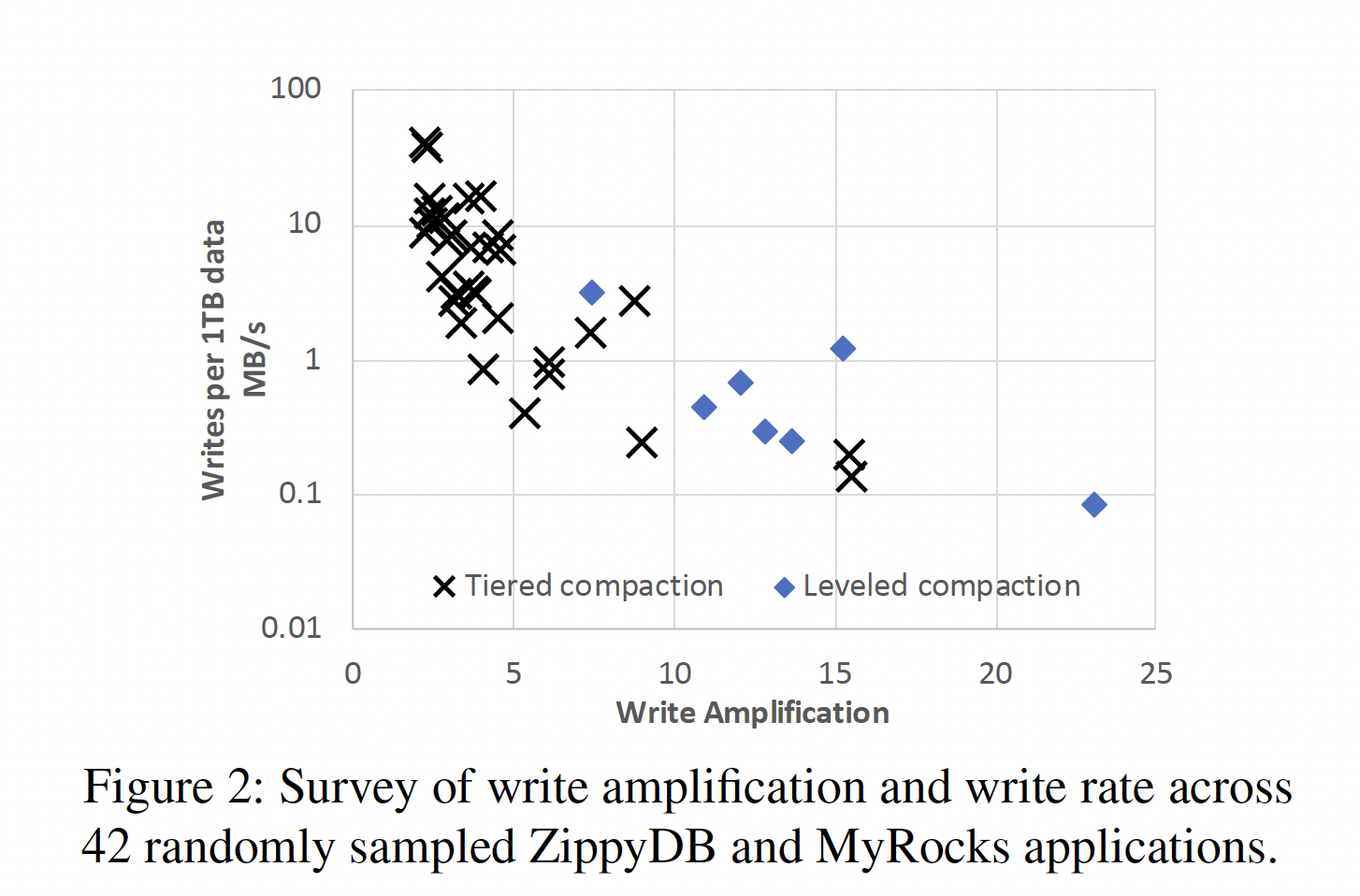
为了证明此观点是正确的,作者给出了若干个 ZippyDB & MyRocks 的实际测试结果用以论证空间才是瓶颈所在:
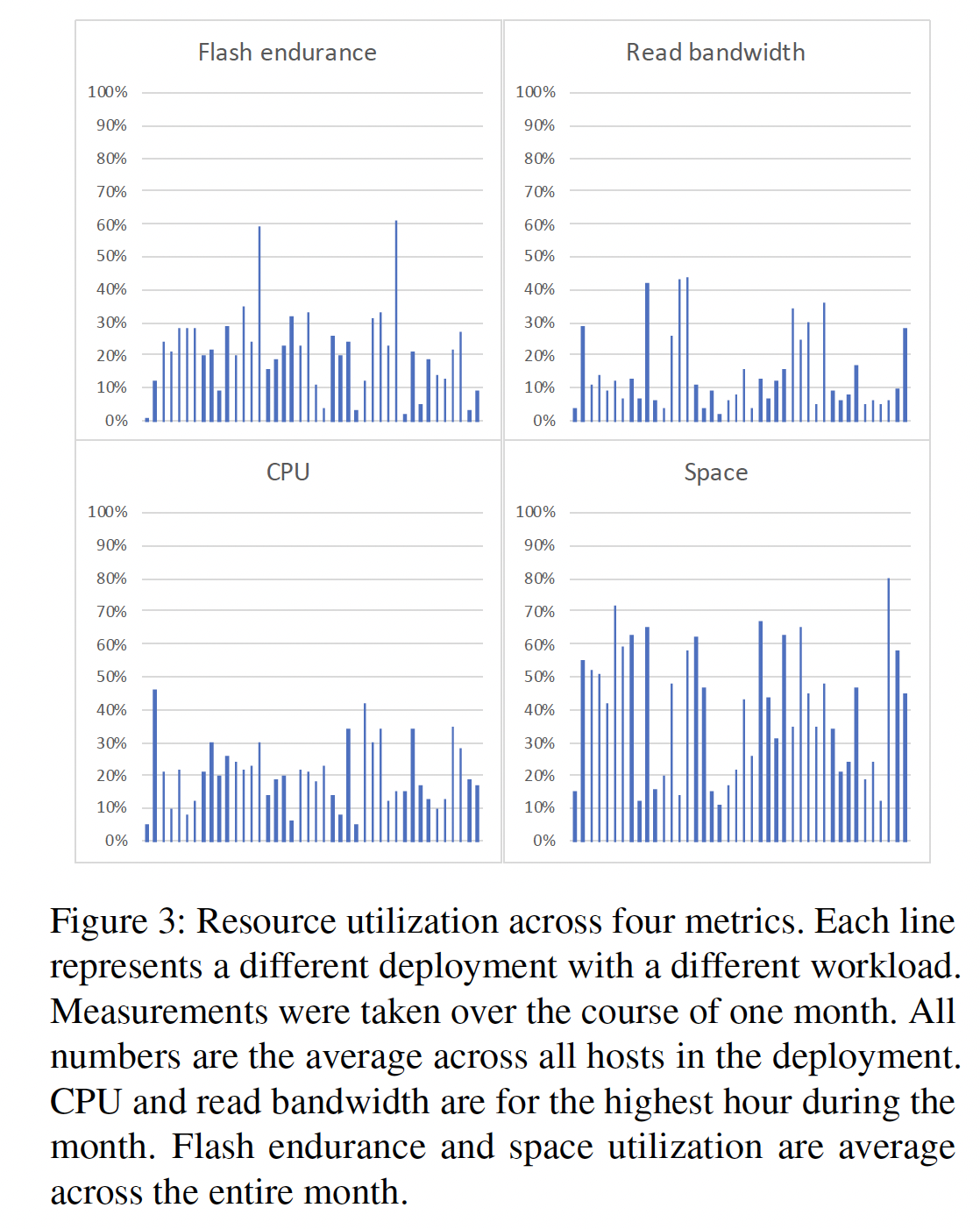
虽然说了这么多无需太担心 CPU 成为瓶颈,作者认为我们还是要去优化 CPU 使用率,为什么呢?因为其他更重要的优化,如空间放大优化都做完了没有可做的了……(这段真不是我瞎写的,原文就是这么说的:Nevertheless, reducing CPU overheads has become an important optimization target, given that the low hanging fruit of reducing space amplification has been harvested.)此外,CPU 和内存还越来越贵了,优化 CPU 使用可以让我们用一些更便宜的 CPU……
一些有助于优化 CPU 使用率的早期尝试包括:前缀布隆过滤器(Prefix bloom filters),在查找索引前就先通过 bloom filter 进行过滤,还有其他一些 bloom filter 的优化。
对于上述论述不甚赞同……
- 作者这是假设这台机器上只跑 RocksDB,上层应用是很轻量级的,把全部 CPU 资源都给 RocksDB 用才没有瓶颈,这显然是很有问题的,有可能上层应用本身就需要很多 CPU 啊,而且作为一个 KV Engine 就把大部分 CPU 资源用完了不太合理吧。这还不要说在共有云等场景下大规模混部的情况了,此时所有空余的 CPU 都是可以用来干其他事的。
- 不知作者为什么认为一台机器上只配一块 SSD 才是最优搭配,根据我的经验这分明是不太好的搭配吧,正因为 SSD 少了存储空间才成瓶颈的,一台机器上使用 2~4 块 NVME SSD 才是目前更主流且合理的方案吧,要是机器上还有多个 RocksDB 实例在同时工作,此时 CPU 显然很容易成为瓶颈吧。
适配新技术
作者列举了一些存储领域的新技术,如 open-channel SSD,mulit-stream SSD,ZNS(Zone namespace,类似抽象得更好的 open-channel SSD),这些都能降低 IO 延迟,然而作者又抛出了绝大部分应用都是受空间制约的这一论据,认为这些技术并没有什么实际用处……此外如果要让 RocksDB 这一层直接用上这些技术会破坏 RocksDB 统一一致的体验,因此更值得尝试的方向是下层文件系统去适配这些新技术,RocksDB 专注于 KV 引擎层该做的工作,而不是去做底层 FS 存储层该做的事。
前面空间制约这一说法不敢苟同……后面的说法倒是的确很有道理,每一层就专注做这一层该做的事吧。
存算一体(In-storage computing)也是个很有潜力的技术,然而尚不确定 RocksDB 要如何用它,以及能从中获得多大的收益,后续会继续关注研究此技术。
远端存储(Disaggregated/remote storage)是目前阶段更有意义的优化目标,上文也提到了 CPU 和本地 SSD 盘很难都同时用满,然而若用的是存算分离的架构则不存在此问题了。对于 RocksDB 来说,对远端存储的优化主要集中在聚合 IO 及并行化 IO 上,此外还有对瞬时网络错误的处理,将 QoS 需求下传至底层系统,提供 Profiling 信息等。
资源使用率优化是存算分离架构最大的优点之一。
持久性内存(Persistent Memory, PMem,又称 Storage Class Memor, SCM)是另一个极有前途的技术,对于 RocksDB 来说有以下这些值得尝试的方向:
- 将 PMem 作为内存的扩展。这个尝试的挑战是在 DRAM 与 PMem 并存时如何优化内存数据结构(Block cache 及 Memtable),并且在尝试利用其非易失性时会有什么额外开销;
- 将 PMem 直接用作系统的主存储介质。SSD 性能作者都认为过剩了当然不会认为这是很好的优化方向;
- 使用 PMem 来保存 WAL 文件。这个想法的问题在于,数据只会在 WAL 文件中停留很短时间,用 PMem 来做是否值得,毕竟 PMem 还是比 SSD 贵很多的。
主要数据结构选择回顾
经过了这么多年的发展,LSM-tree 这一基本数据结构是否还合适呢?作者给出的答案是,Yes!LSM-tree 至今还很适合 RocksDB 使用。主要原因是 SSD 的价格还没有降到足够低的程度,即可以让大部分应用都不在意其寿命损耗的程度,此类应用只是很少一部分应用。然而,当 Value 很大时,分离 KV (如 WiscKey)可以显著降低系统写入放大,所以此功能也被加入到了 RocksDB 中(被称为 BlobDB)。
4 应用于大规模系统中的经验教训
资源管理
在大规模分布式数据存储系统中,通常都会将数据分为若干个 Shard,再把不同 Shard 分配到不同存储节点上。单个 Shard 的大小通常是有上限的,原因是 Shard 是负载均衡和多副本的基本单位,需要能在不同节点间自动拷贝。每个服务节点上通常都会有数十个或数百个 Shard。在使用 RocksDB 的通常实践中,一个 RocksDB 实例只用于管理一个 Shard,因此一个服务节点上也就会有很多 RocksDB 实例在同时运行,这些实例可以运行在同一地址空间下,也可运行在不同地址空间下。
这里分别就是多线程和多进程模型吧。
一台 Host 上会运行多个 RocksDB 实例的事实让资源管理变得更为复杂,因为资源需要同时在全局(整个 Host)和局部(单个 RocksDB 实例)两个维度上进行管理。
当不同实例运行在同一个进程内时资源管理相对较为简单,只要限制好各种全局资源,如内存,磁盘带宽等的使用即可。RocksDB 支持对每类资源都创建一个资源控制器(resources controller),并将其传递个各实例,以实现实例内的局部资源管理,这个资源管理还是支持优先级的,可以灵活的在不同实例间分配资源。
然而若不同实例时运行在不同进程上时,资源管理就会变得更有挑战性。解决此问题有两个思路:
- 每个实例配置成保守的使用资源的模式,即先设置一个较低的限额,当出现瓶颈后再尝试去用更多的资源。此方案的缺点很明显,全局的资源使用率不是最优的。
- 实例间通过 ICP 或其他机制共享资源分配信息,以此实现一个更优的局部资源分配。这条路上 RocksDB 还有很多工作需要做。
此外,另一个经验教训是,随意使用独立的线程会导致很多问题,这会使得总的线程数变得很多且不可控,进而导致线程切换开销增大及很痛苦的 debug 过程。一个更好的选择是使用线程池,这可以根据实际情况去控制总的线程数量。
WAL 文件的处理
传统的数据库都是使用 WAL 文件来保证数据持久性的,然而大规模分布式存储系统更多的是依赖于不同节点上的多副本来保证这一点的,单节点的数据损坏可以通过其他节点来进行修复,对于这类系统来说,RocksDB 的 WAL 文件就没那么重要了。进一步,很多一致性协议(如 Paxos,Raft 等)有其自己的 Log,这种情况下 RocksDB 的 WAL 文件就完全没用了。
因此 RocksDB 提供了三种不同的 WAL 策略可供选择:
- 同步 WAL 文件写入;
- 缓冲(buffered)WAL 文件写入,即在后台以低优先级异步刷 WAL 文件;
- 没有 WAL 文件。
删除文件限速
RocksDB 底层的文件系统通常是选用 SSD-aware 的文件系统,如 XFS,此类文件系统在删除文件时可能会显式的向底层 SSD 固件发送 TRIM 命令。此行为通常有助于提高 SSD 的性能及寿命,然而某些时候也会导致一些性能问题。TRIM 命令其实是没那么轻量级的,SSD 固件在收到 TRIM 命令后会更新其地址映射关系,此行为有可能需要写入 FTL 日志(journal),而 FTL journal 是位于 Flash 上的,这又有可能会触发 SSD 内部的 GC,进而导致大量的数据迁移,此行为会干扰前台写入造成写入延迟的上升。为解决此问题,RocksDB 引入了一个速率限制器来限制 compaction 后并发删除的速度。
数据格式兼容性
大规模的分布式系统之所以叫大规模了,当然是因为整个系统中的机器数很多喽,此时升级肯定是增量式进行的,没有任何实际生产系统会对所有节点做同步升级。因此需要保证两种基本兼容性:
- 新老版本间数据的兼容性,因为要考虑到回滚,向前兼容性和向后兼容性都是需要的;
- 不同版本运行在同一集群下数据的兼容性,因为分布式系统会在节点间搬移数据,要考虑二者并存的时候整个系统是正常的。
如果不保证这些兼容性就会给运维带来极大的困难。对于向后兼容性(backward compatibility)来说,RocksDB 要能识别之前版本的数据,这的代价通常是软件复杂度;而向前兼容性(forward compatibility)通常是更难保证的,这要求老版本要能识别新版本的数据,RocksDB 通过 Protocol Buffer 等技术来一定程度的保证了至少一年的向前兼容。
backward compatibility 相对比较好做,顶多就是代码写得复杂点;然而 forward compatibility 要困难的多,甚至是在很多时候根本就是不可行的,一个系统的 forward compatibility 如何很大程度上是取决于设计之初设计者的远见与前瞻性的。
配置方式管理
RocksDB 的一大特色就是其高度可配置性,这也是它能用于满足各种工作负载需求的原因所在,然而此时配置管理也就变得很有挑战性了。最初 RocksDB 的配置方式类似于 LevelDB,有哪些配置项及其默认值等都是写死在代码中的,这种方式有两个问题:
- 某些配置项是和磁盘上的数据密切相关的,如果数据是根据 A 配置生成的,而另一个实例使用 B 配置去读取就会发生问题;
- RocksDB 版本升级有可能会修改代码中的默认值,这在某些时候会造成一些非预期的结果。
为解决此问题,RocksDB 支持针对每个数据库使用不同的配置文件,而非一个 RocksDB 实例只能用一个统一的配置文件。此外还提供了一些辅助工具:
- 检查配置文件和实际数据库数据间的兼容性工具;
- 数据库数据迁移工具,可以根据期望的配置文件来进行数据重写迁移。
另一个更严峻的问题是 RocksDB 的配置项实在是太多了,这是 RocksDB 早期之所以能得到广泛应用的一个原因,然而过多的配置项也让配置的复杂性和混乱程度变得很高,要弄清楚每个配置项是干嘛的基本是不可能的。这些配置项如何配置才是最优的不仅取决于 RocksDB 的运行环境,还取决于其上层应用,还有上层应用更上层的负载情况等等,这些都会让调参变得极为困难。
这些真实世界中遇到的问题让 RocksDB 的开发者们重新检视了其最初的配置支持策略,开始努力提高 RocksDB 开箱即用性能及简化配置项。目前开发的重点是在保持高度可配置性的基础上提供更强大的自适应性(automatic adaptivity),要同时做到这两点会显著增加代码维护的负担,然而开发者们认为这是值得的~
多副本及数据备份支持
RocksDB 本身是一个单节点的库,使用 RocksDB 的应用需要自己处理多副本及备份问题,不同应用的处理方法不尽相同,因此 RocksDB 需要对此提供恰当的支持。
在新节点上重新拉起一个副本有两种策略:
- 逻辑拷贝(Logical copying),从源副本读数据再写到目标副本去。对于这种方式,RocksDB 提供了 Scan 接口支持,且提供了让这类 scan 尽量少影响在线服务的能力,如这类操作读到的数据不加到 Cache 里面;目标端提供 bulk loading 支持。
- 物理拷贝(Physical copying),直接把 SSTable 及其他文件拷贝过去。RocksDB 对这种方式的支持在于,可以提供当前数据库用到的 SSTable 及其他文件不会被删除或修改的能力。支持物理拷贝也是 RocksDB 选择将底层架在一个文件系统而非裸盘上的重要原因,这可以方便使用文件系统自己提供的工具来实现这一 Copy,开发者们认为,直接使用裸盘带来的性能收益并不比上述优势的收益更大。
备份也是很多数据库或其他应用所需的一个重要功能。备份与多副本一样也有逻辑和物理两种方式,然而与多副本不同的是,应用通常需要管理多个版本的备份数据。尽管大部分应用都实现了其自己的备份策略,RocksDB 也提供了一个简单基本的备份引擎。
5 错误处理的经验教训
静默错误出现概率
由于性能原因,RocksDB 一般不使用 DIF/DIX 等 SSD 提供的数据保护功能,而是使用最为通用的校验和策略。根据作者的观测,RocksDB 层面的错误在 100PB 规模下大概每 3 个月就会出现一次,更糟糕的是,大约 40% 的情况下,错误已经被扩散到多个副本里去了。
多层次的数据保护
数据损坏越早被检出系统的可用性及可靠性就会越好,大部分基于 RocksDB 的应用都使用不同机器上的多副本策略,此时检测到一个副本校验和错误后可以根据其他副本进行修复,前提是正确的副本还存在。
目前的 RocksDB 校验和保护机制可分为 4 层(含计划中的应用层校验和):
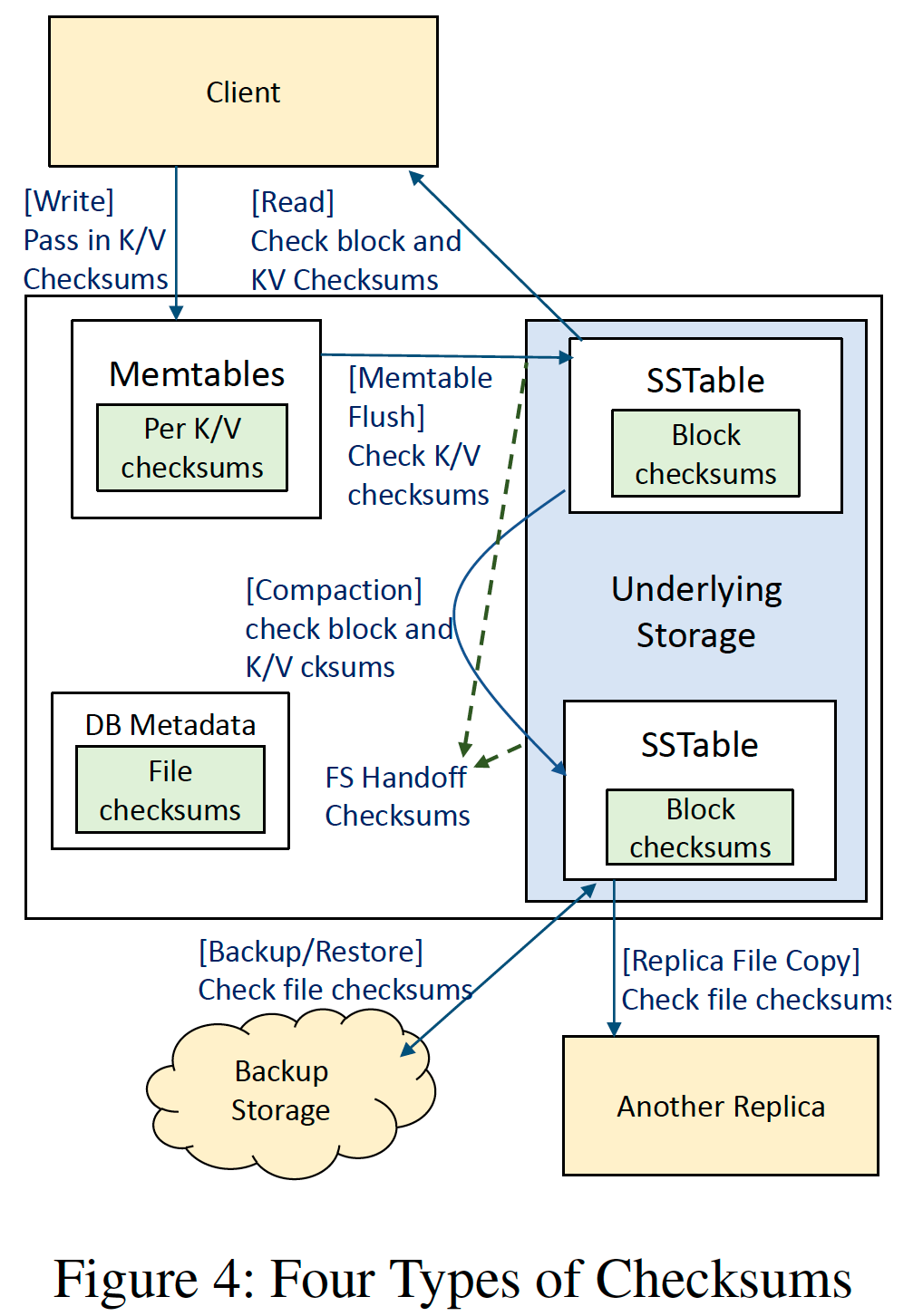
- Block checksum。源于 LevelDB,SSTable 中 Block 级别的校验,会在每次读取时进行检查,用于防止由于底层文件系统导致的数据损坏;
- File checksum。在 2020 年加入,整个 SSTable 的校验,保存在 SSTable 的 meta 字段中,用于防止在传输整个 SSTable 过程中发生的数据损坏;
- Handoff checksum。用于保护 WAL 文件的机制,核心思想是在写入时将数据及其对应的校验码一起发给底层文件系统,底层文件系统对每次的增量写入进行校验,以此避免写入 WAL 这一过程中发生的错误。然而不幸的是,绝大部分本地文件系统是不支持此类 API 接口的。不过对于远端文件系统来说,可以通过修改 API 接口来支持此类端到端的保护功能。
- K/V checksum。计划中的功能,需要修改 RocksDB 的 API 接口并要上层应用配合实现,为每个 kv 都加入校验,这是最彻底的端到端的数据保护措施。
分级错误处理
RocksDB 遇到的大部分错误都是底层文件系统返回的错误,最初 RocksDB 处理这些错误的方式就是不处理,即直接将这些错误抛给上层应用或永久停止写入。目前开发者们更倾向仅在 RocksDB 自身无法处理或恢复时才中断 RocksDB 的正常流程,实现这的基本方法就是对某些暂时性错误在 RocksDB 层面就进行重试。上层收到 RocksDB 的错误后一般处理方法都是进行实例迁移,RocksDB 自身进行了重试后上层因此造成的实例迁移就会少很多。
6 KV 接口设计的经验教训
版本及时间戳
核心的 KV 接口是如此的通用,以至于基本所有的存储负载都可以被 KV 接口所满足,这就是 KV 存储这么流行的原因了。然而对某些应用来说,这么简单的接口可能会制约其性能。比如要想基于 KV 接口做 MVCC(Multiversion concurrency control,多版本并发控制)的开销就会很大。
RocksDB 内部是有一个 56-bit 的序列号用于区分不同版本的 KV 对的,也支持快照(Snapshot)功能,生成了一个 Snapshot 后此时的所有 KV 对都是不会被删除的,直到显式的释放了此快照,因此同一个 Key 是可以有多个序列号不同的 Value 的。
然而此种简单的多版本机制是没法完全满足很多应用需求的,原因在于此机制存在一些局限性:
- 要读到历史数据的必要条件是历史数据的 Snapshot 已经存在了,RocksDB 是不支持对过去时间再进行快照的;
- 上述序列号是单个 RocksDB 实例自己生成并维护的,只保证其是一个递增的序列号,用户写入时也不能指定此序列号,因此基本是没法建立一个全局跨 Shard 的一致性读(由于不同实例间的序列号没有可比性)。
应用想要绕开这些限制只能在 Key 或 Vaule 中自行编码加入时间戳,然而这会导致性能下降:
- 在 Key 中编码时间戳会让查询变得低效,原因是之前的单次 Query 变成了范围 Scan;
- 在 Value 中编码时间戳会让写入变得低效,因为要更新 Vaule 必须要进行 RMW(Read-Modify-Write) 操作。
因此在 KV 接口层面就支持指定时间戳会是一个更好的解决方案,目前 RocksDB 对此已经提供了基本的支持。以应用自行在 Key 中编码时间戳的性能为基准,原生带时间戳的 KV 接口性能如下:

可以看到至少有 1.2 倍性能提升,原因在于查询操作可以使用正常 Query 接口而非 Scan 接口了,此时 Bloom Filter 等就都可以起作用了。此外 SSTable 包含的时间戳范围可以加入到其元信息中了,这就有助于在读的时候直接跳过不符合要求的 SSTable 文件。
开发者们认为,此功能有助于上层应用实现 MVCC 或其他分布式事务功能,然而并不考虑开发更复杂的多版本功能,原因是更复杂的多版本功能使用起来并不那么直观,也可能会被误用;且为了保存时间戳需要更多的磁盘空间,也使得接口上与其他 KV 系统间的可移植性变差。
7 相关工作
这部分主要就是介绍在存储引擎库,基于 SSD 的 KV 存储系统,LSM-tree 优化,大规模存储系统这几方面上还有些什么研究,感兴趣的可以去看看原文。
8 未来的工作及一些开放问题
除了上文提及的支持远端存储,KV 分离,多层次校验和,应用指定时间戳外,还计划统一 Leveled 及 Tiered compaction 策略和增强自适应性,此外还有些开放问题:
- 如何使用 SSD/HDD 混合存储来优化系统效率;
- 当存在很多删除时如何尽量保证此时的读性能;
- 如何优化写入限流算法;
- 如何高效的比较两个副本,以确定其包含相同的数据;
- 如何最好的使用 PMEM,此时还该继续使用 LSM-Tree 么?如何支持多存储层级;
附录 A. RocksDB 发展路线图
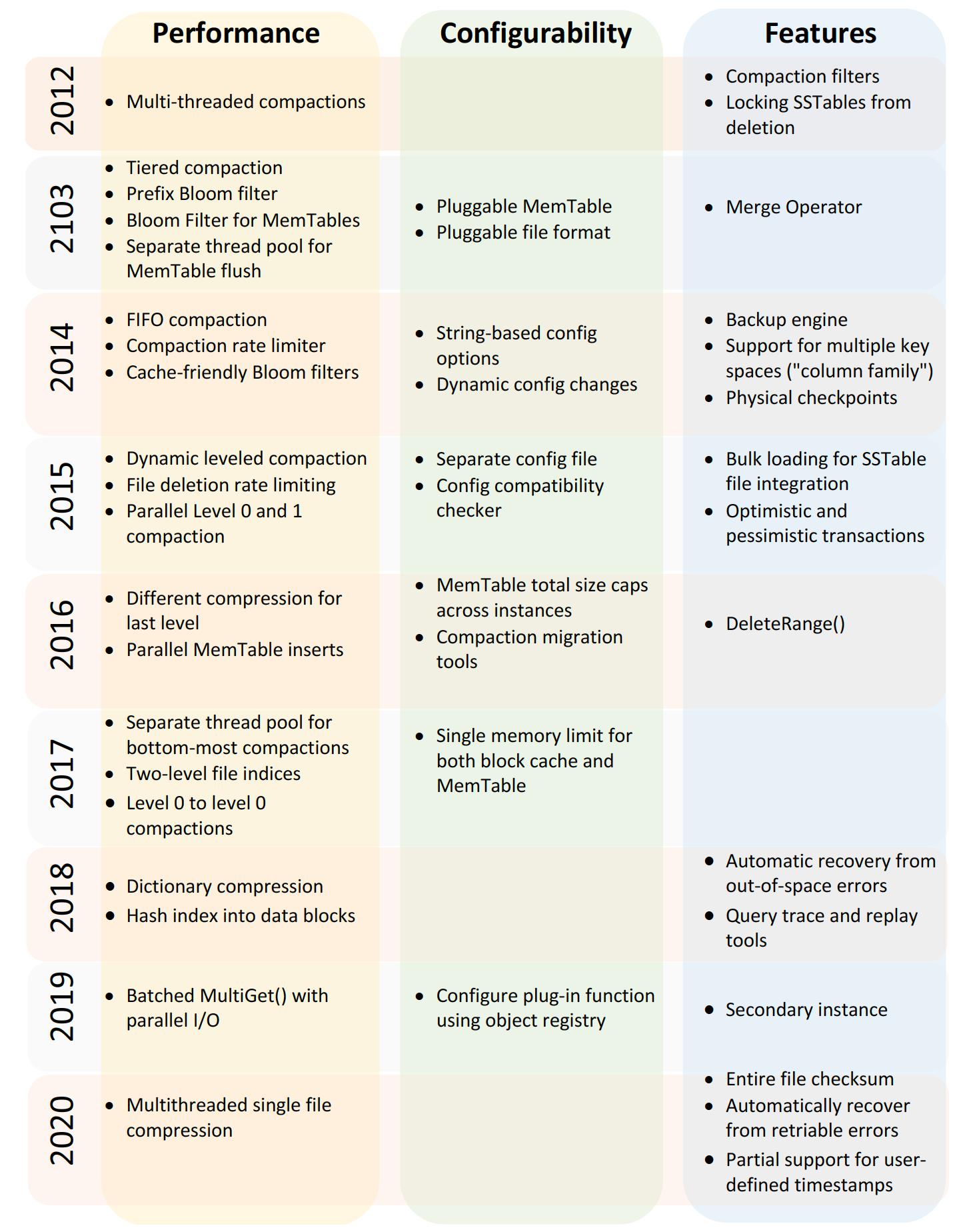
很不错的图~可以看到 RocksDB 性能上的优化主要聚焦于 Compaction 及 Bloom Filter 展开~
附录 B. 重要结论总结
- 一个存储引擎能通过调参来适应不同工作负载是很重要的;
- 对于使用 SSD 的大部分应用来说,系统瓶颈是在 SSD 容量上;
- 降低 CPU 开销也变得越来越重要;
- 如果一台机器上运行了多个 RocksDB 实例,那全局的资源管理就会变得很必要;
- 提供不同的 WAL 文件处理方式可以给上层应用带来性能提升;
- SSD TRIM 是个好命令,然而需要对文件删除操作进行限速以避免偶发性的性能问题;
- RocksDB 需要同时具有向前及向后兼容性;
- 配置的自适应性对于简化配置管理来说很有帮助;
- 需要恰当的支持多副本及数据备份;
- 数据损坏发现的越早越好,而非最后用到时才发现;
- CPU 及内存导致的数据损坏很罕见,然而是有可能发生的,此类数据损坏有时是不能被多副本所修复的;
- 数据完整性保护需要覆盖全系统;
- 用户通常是期望 RocksDB 能从暂时 IO 错误中自动恢复过来的;
- 错误需要根据其原因及后果不同而采用不同处理方式;
- KV 接口是通用的,然而会有些性能局限性,增加一个时间戳可以很好的平衡性能和简单易用性。
附录 C. 设计之初一些不太合适的观点
- 对用户来说可自定义的程度越高越好;
- RocksDB 无法处理类似 CPU 位反转这类错误;
- 一旦发生 IO 错误就直接停止工作是可以接受的。
参考资料: