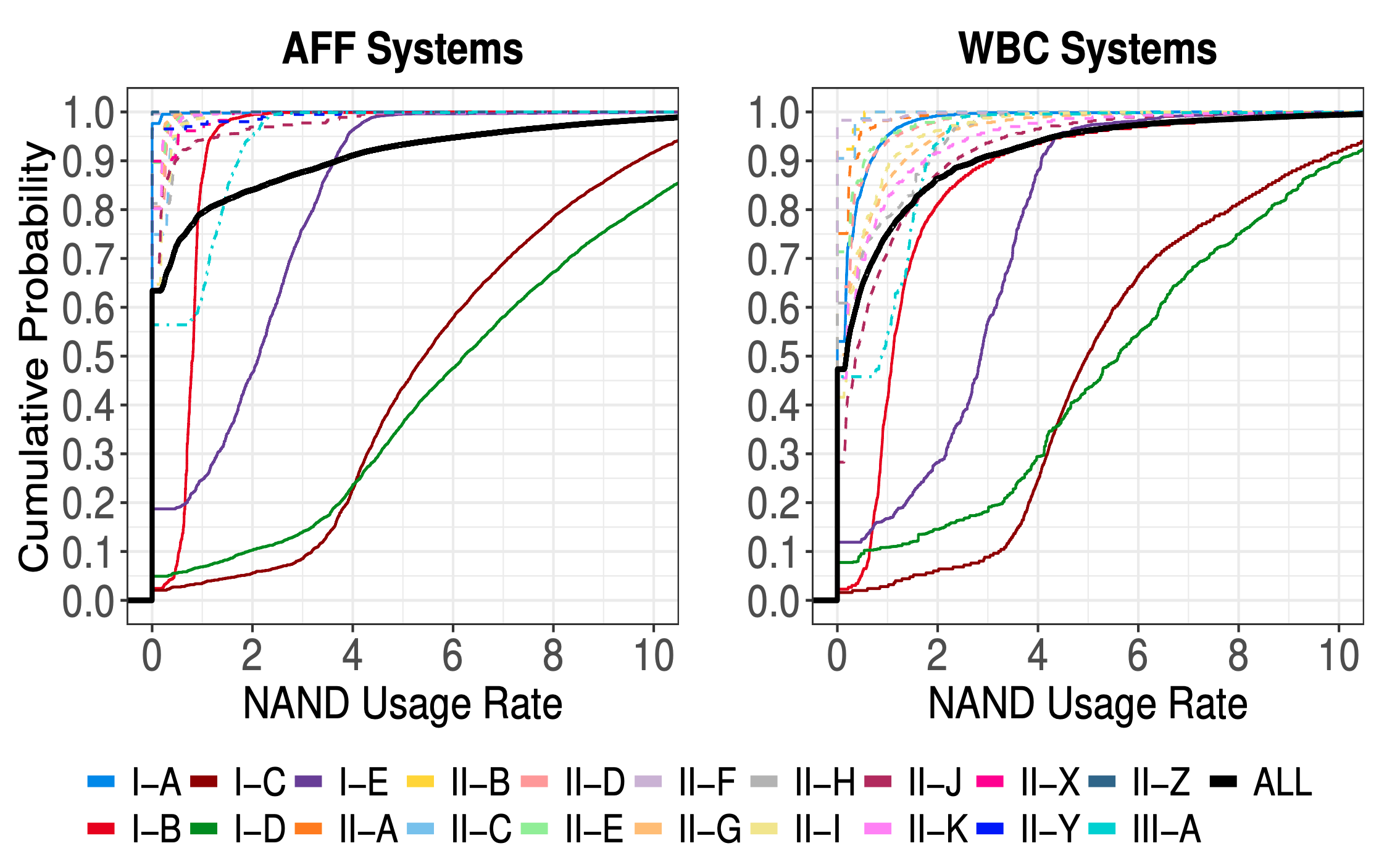
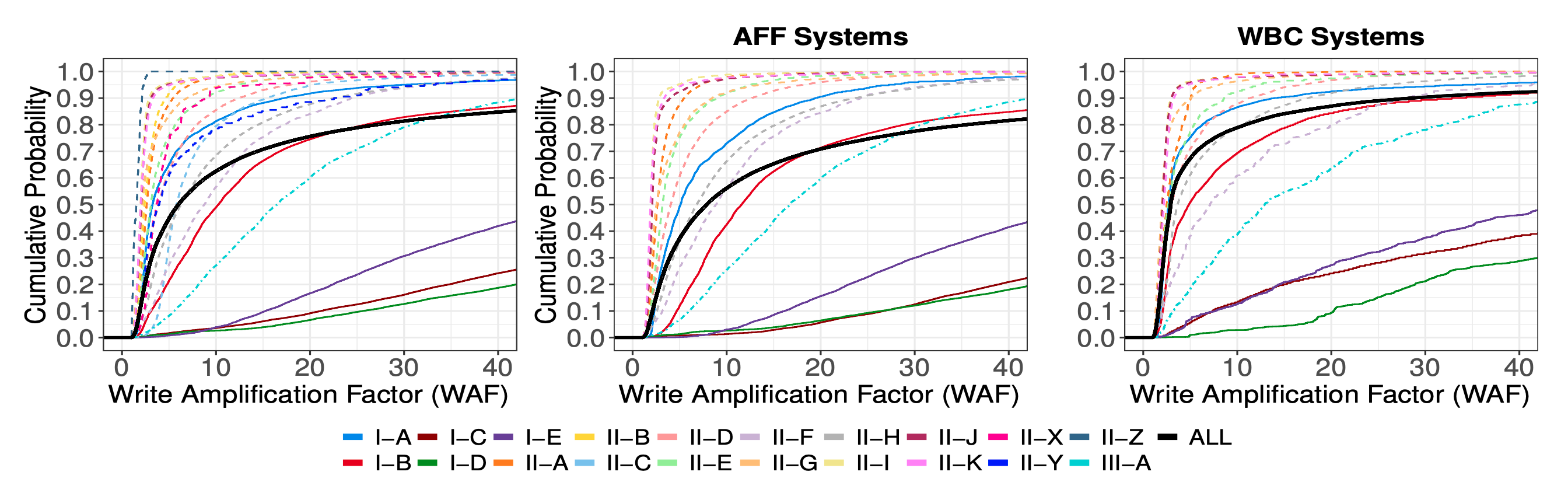
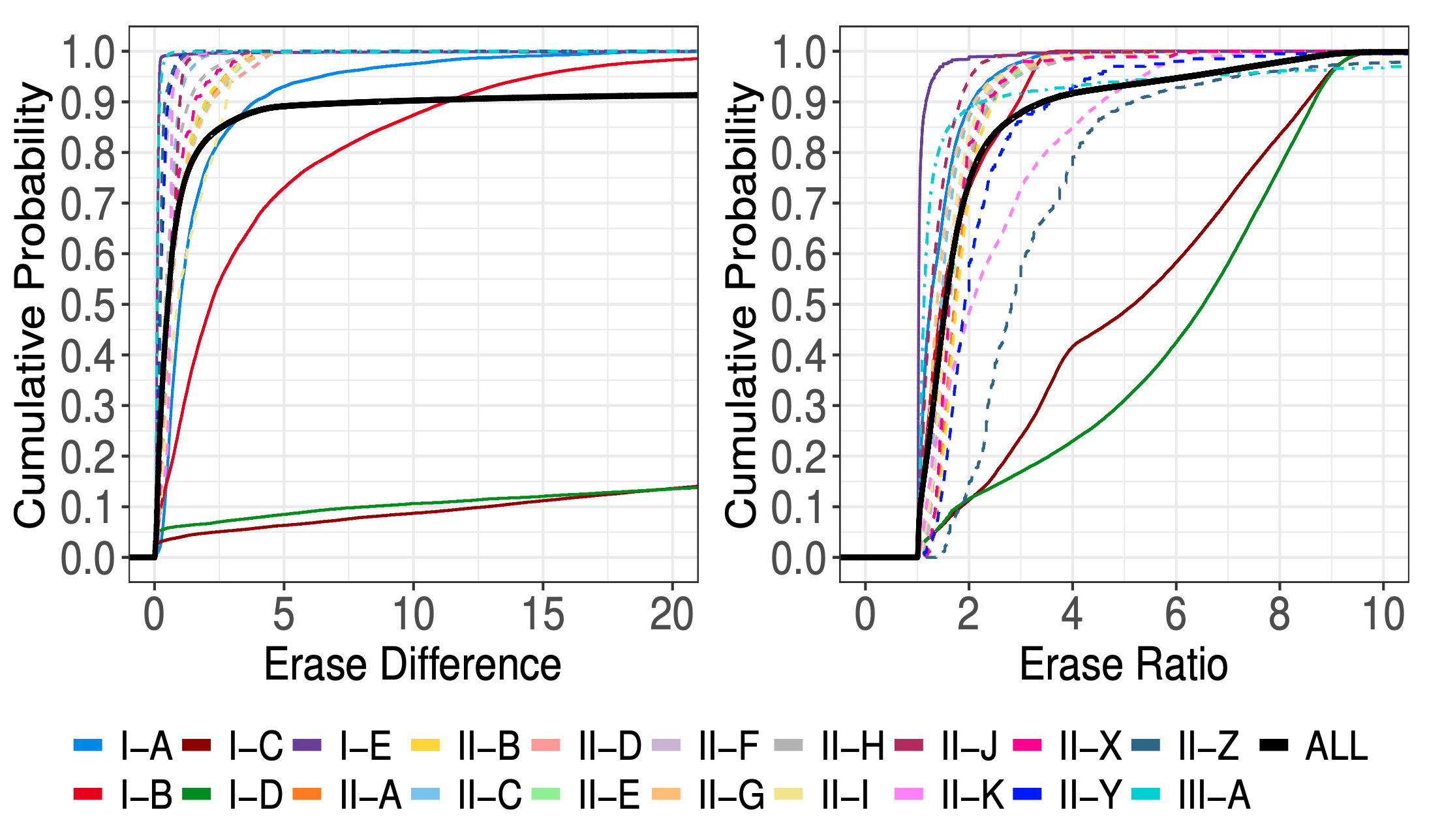
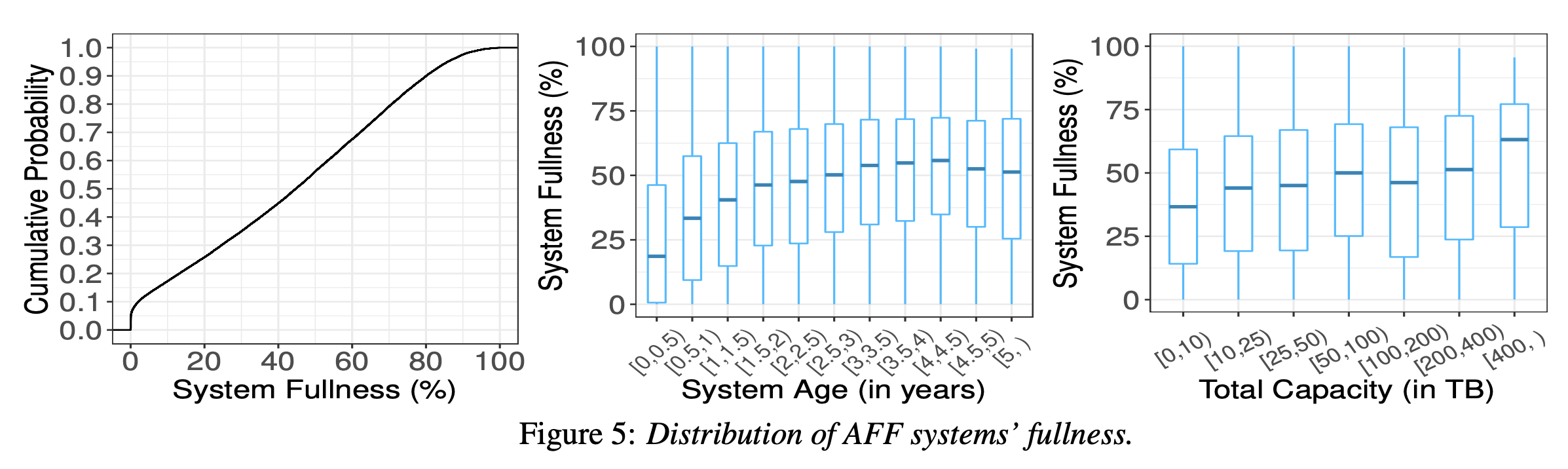
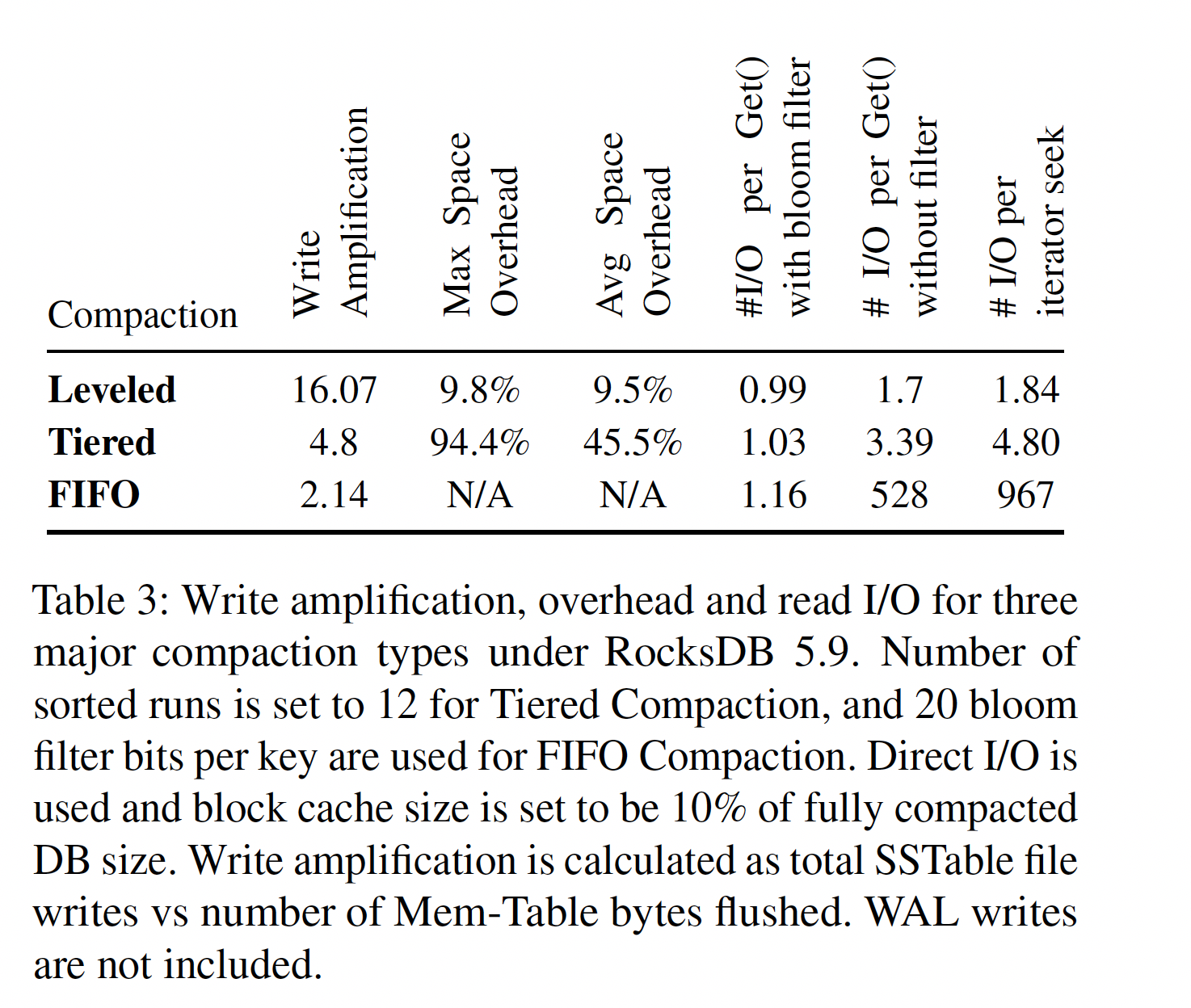
作为一个爱折腾的程序员,这几年来也陆陆续续折腾过不少东西,本文就来记录分享一下家庭网络及 NAS 存储搭建方面的过程吧。最简单的家庭网络结构就是直接使用电信联通等运营商提供的光猫即可,现在的光猫都自带了无线 WiFi 功能,这就可以满足最基础的需求了。然而这显然无法满足爱折腾的我们诸多高级需求,因此我们需要充分发挥折腾精神,打造一套强大的网络出来。
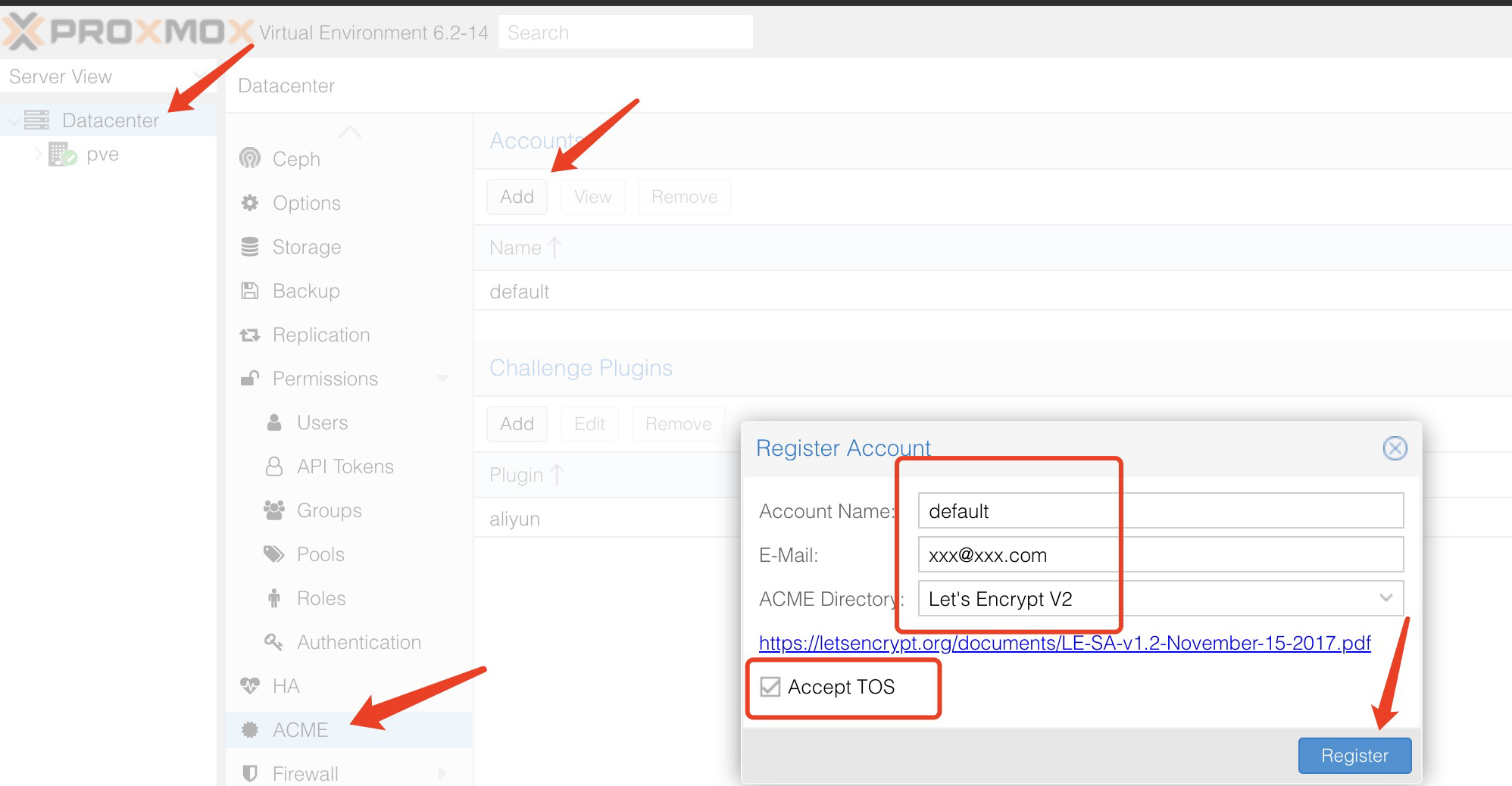
整体拓扑结构
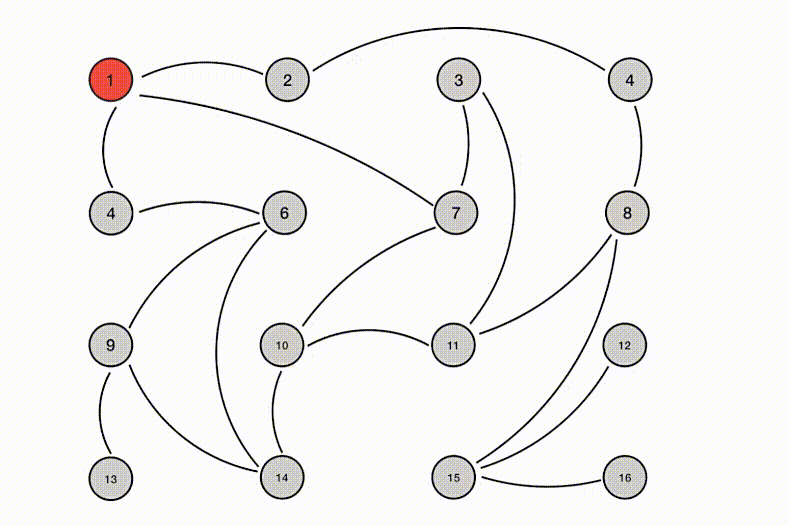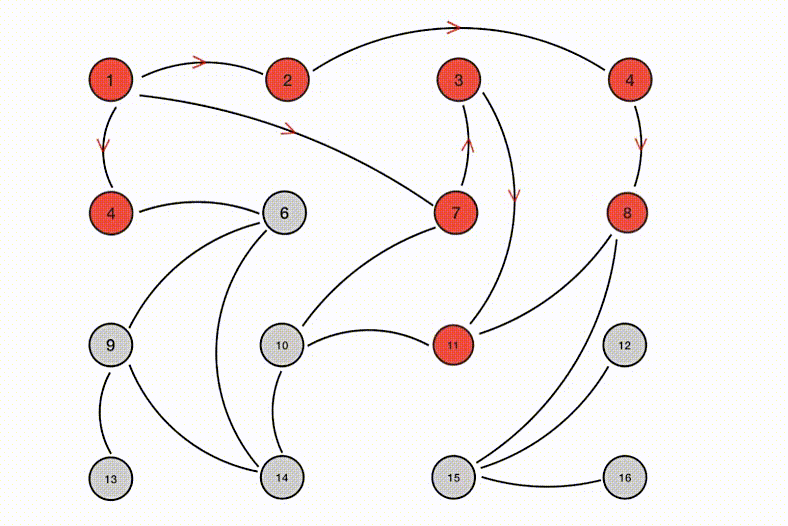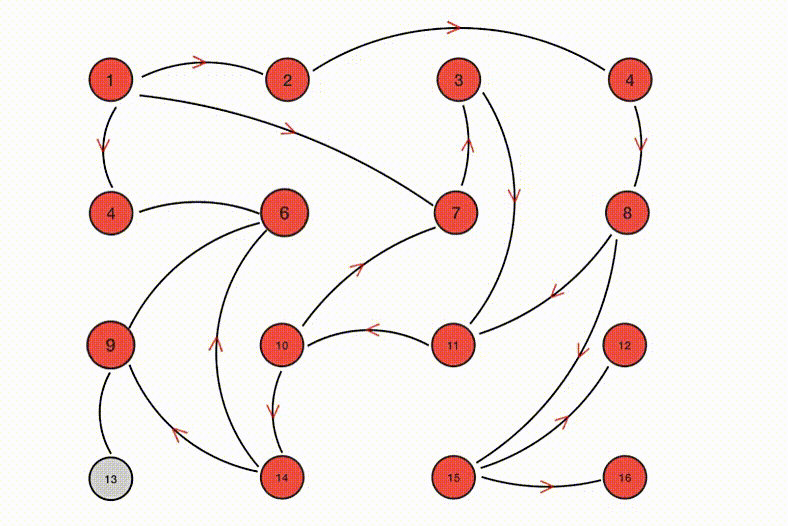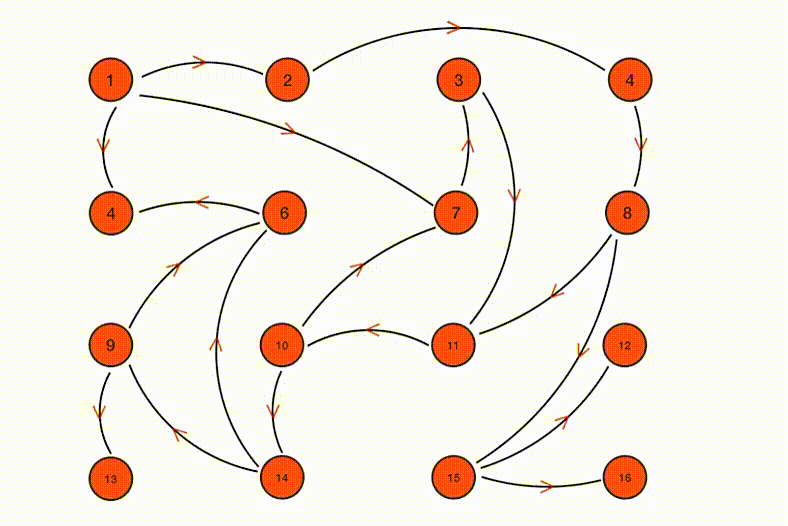
直接上整体拓扑结构图吧:
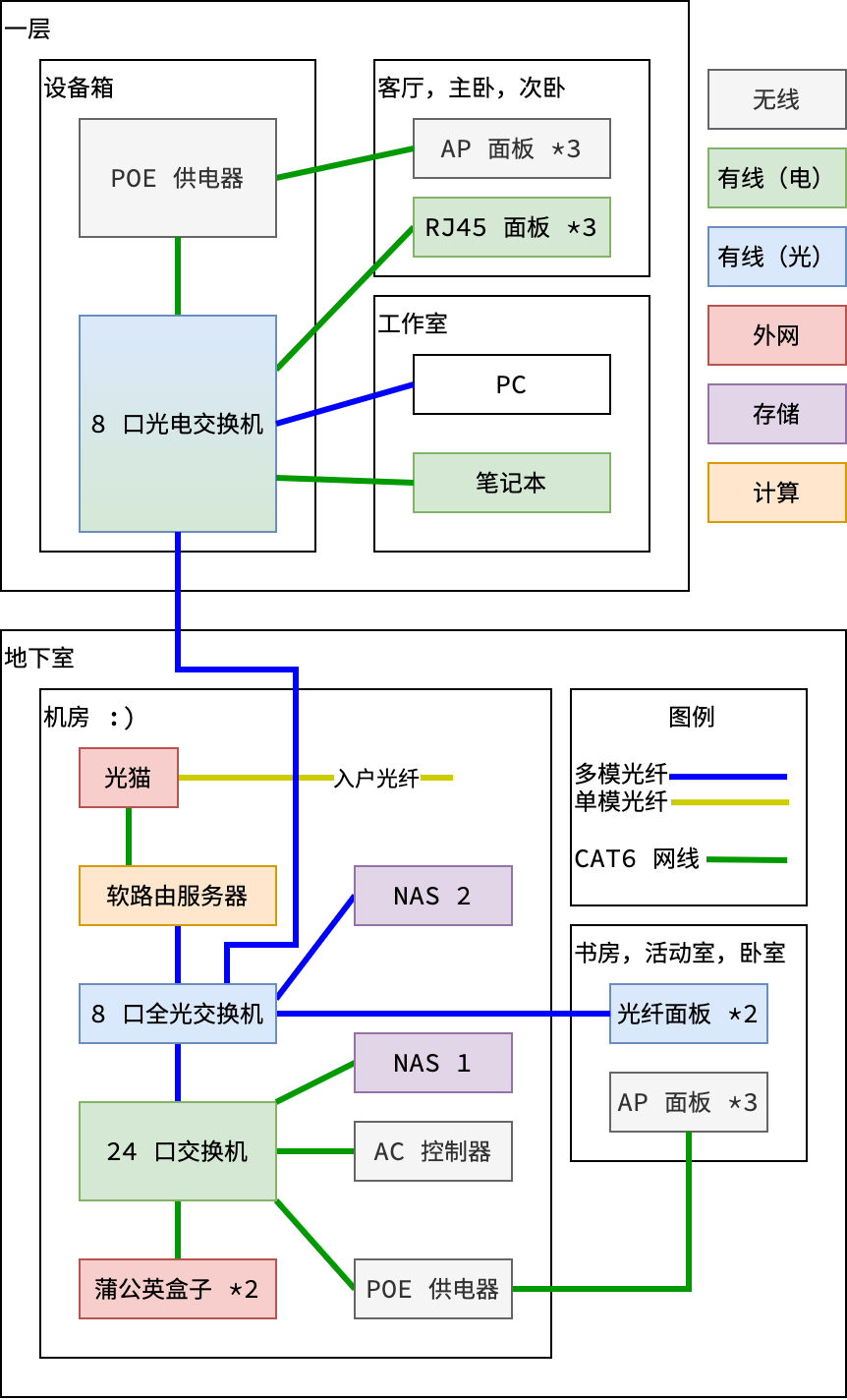
电视这类终端设备图中就省略了,反正遵循能接有线尽量用有线的原则就好。图中的设备下文会一一进行介绍,绝大部分设备都是放在所谓的机房中,当然家里面不会有真正的机房啦,实际上这只是一个隐秘的小角落:)为了方便放这些现有的设备,再考虑到将来东西只会越来越多,于是买了个机柜:

这是个标准 32U 机柜,尺寸 1600 x 600 x 600。机柜的使用体验其实是比一般的柜子好很多的,散热,理线,安装都很方便,毕竟是专门为此类应用设计的。机柜的样子和功能都大同小异,在淘宝上随便找一家销量高点靠谱的就好,32U 的价格在 ¥600~1000 不等。不过一般标配的隔板数量都比较少,而机柜的隔板是可以任意添加的,因此可以联系卖家多加几块隔板。
机柜里面诸多设备供电当然也可以用普通插线板,不过更好的选择是使用 PDU 专用电源插座,这种插座可以直接固定在机柜背后:

插座选正规大品牌一般都不会有什么问题,不过需要注意的是,16A 插座的插头是要更粗一些的,就是和某些空调专用插头一样,没法插到普通三孔插座里去,选择的时候要考虑到此问题。
机柜什么都好,唯一的问题是放在家里看着不那么温馨和谐,然而这不是问题,可以在外面做个可移动的柜子把这个隐秘的小角落围起来!因为有了一个隔离的小角落,设备噪音等问题就不是很关键了;家庭使用设备再多也是比不过正经机房的,而且家里夏天也都会开空调,因此整体散热一般来说也不是大问题。

下面就来具体介绍下这些小宝贝们吧。
外网接入
外网接入没有太多可折腾的,光纤入户的话基本只能用运营商提供的光猫,而且现在越来越多的运营商提供的设备是所谓的 SDN 光猫了。这个光猫那是真的垃圾难用啊,我手头上的是电信提供的烽火通信 HG7143D,基本什么可配置的东西都没有全被阉割了,唯一能配置的就只有无线 WiFi 的开关,连个 DHCP 都不能配置,强制开启且固定为 192.168.1.0/24 网段。
最早尝试过把光猫的 LAN 口接到交换机上,再通过交换机连接自己的其他设备,这方案勉强也能用,然而经常出现奇怪各种问题。于是目前的方案是把这个光猫和家里的其他设备彻底隔离开来,自带的 WiFi 啥的当然是第一时间全关了,只通过一条网线和软路由服务器点对点连接。所谓的软路由服务器其实就是一台普通台式机,安装了 PVE 作为虚拟化平台,在虚拟机中运行 OpenWRT 等软路由系统;硬件上是有多个网口的,因此可以实现单独一个网口用于连接光猫。这台服务器的情况下文再来详细介绍。
软路由上将家庭内网的网段换一个不要使用 192.168.1.0/24,这样隔离一下光猫就彻底不会来干扰其他设备了,老老实实的只需要提供外网接入就好了。这个方案也减少了对光猫功能的依赖性,将来无论再换个什么设备都可以直接替换,可谓是我目前想到的最完美的方案了。
目前还剩下未能解决的痛点问题是,由于家里入户光纤只有一条,没法简单的同时接入电信和联通宽带。二者的波长都是一样的,显然不能直接简单的共用一条光纤。单独再拉一条新的光纤看起来也不太现实。所以唯一的解决方案就只能是使用波分复用器等设备进行分离了,先不说设备很贵的问题,这方案在自己家这端还好说,想怎么搞就怎么搞,然而单元接入点那端基本是没法搞定的,此类设备都是有源设备,也就是必须要单独供电的,放在单元接入点那怎么供电呢……
有线局域网
这是网络中最复杂的部分了,从上面的拓扑图中也可以看到,我选择了网线 + 光纤混合在一起的解决方案。主要原因是想要享受超过 1Gbps 的网络带宽,而 10Gbps 的万兆网络方案基本都以光网络为主,电口只有少数 2.5GbE 的,而且价格上比光口还要贵。当然,实际上绝大部份场景下 1Gbps 是足够用的,能用到超过 1Gbps 的情况是很少的,不过折腾嘛,总要搞点看上去很厉害的东西喽,而且难说未来就能用上了呢……
交换机
光网络的核心设备当然是光交换机了,我选择的是 TP-Link 的 TL-ST1008F,这是一款很小巧优雅的 8 口全光交换机,所有口均为 SFP+ 万兆接口,采用无风扇设计。选择这个型号的原因只有一个,它足够便宜,基本是目前最便宜的万兆光交换机了。这款交换机是 2 年前买的,然而直到现在也是最佳的选择,没有比它更便宜的了。
这个交换机最大的缺点自然是它只有光口没有电口了,然而这正符合我的需求~
显然目前还做不到家里面的设备全用光纤,因此自然要有支持光电转换的交换机了,这就是拓扑图中的 8 口光电交换机和 24 口交换机了。为什么有两个呢,因为家里有两层,楼上一个楼下一个。
24 口交换机选用的是 TP-Link 的 TL-SH1226,这款交换机有两个 SFP+ 万兆光口和 24 个标准千兆 RJ45 端口,也是属于比较便宜的产品。
另一个 8 口光电交换机则是 QNAP 威联通的 QSW-308-1C,这是一款完全针对家用设计的小巧美观的交换机。为什么选择这一款交换机呢,主要是因为它足够小,而且采用了无风扇设计十分静音,很适合放在客厅的弱电箱旁边。这台交换机虽然小,然而接口却十分丰富 —— 8 个 1GbE RJ45 接口,2 个 10GbE SFP+ 光口,还有一个极为特别的 10GbE/5GbE/2.5GbE/1GbE SFP+/RJ45 组合自适应端口。市面上 10GbE 的电口产品已经很少了,这种全速率兼容的光电两用口更是独一无二的设计。
目前 1GbE 电口用了 6 个 —— 3 个 RJ45 面板及 3 个 AP 面板;2 个 10GbE SFP+ 光口都用到了 —— 1 个用于连接 TL-ST1008F 全光交换机,另一个用于连接 PC 主机;至于那个组合端口,目前是当作 2.5 GbE 电口来用的,使用了 Cat 7 网线来连接笔记本电脑。整体资源使用率还是很高的,并没有浪费那么多的接口~
光模块
不同于 RJ45 接口,光纤并不是直接插到交换机等设备上的,SFP+ 接口需要插入的是 SFP+ 光模块,光模块再和光纤连接。光模块的型号相对比较复杂,有不同的接口(LC,SC,电口 等),不同的传播模式(多模 SR,单模 LR 等),此外还存在一定的兼容性问题(和网卡或交换机的兼容性),因此选购的时候需要去先补充些基础知识,再多和商家交流下才行。不过一般不兼容的话都是可以退货的,所以可以先买来看看再说。同样是考虑到兼容性,一条光纤两端用的模块通常都是选同一型号的,不同型号的能不能混着用就不确定了。
这里还有一个坑,一般光纤都会考虑长距离通信问题,因此很多光模块的宣传重点是我们的模块 10km 还能用云云,然而家里面就几十米,10km 能用反而几十米难说就不能用了……原因是光强度太强的话接收端有可能会出现饱和问题,此时通信会很不稳定。之前买过一对光模块就发现这个问题了,ping 丢包率实在太高,和厂家的工程师沟通了好久才找到原因。解决方案也很简单粗暴,加上一个几块钱的衰减器即可。当然不是所有光模块都有这问题的,也有些模块短距离通信不加衰减器也不会出现饱和问题。
除入户光纤使用的是 SC 接口外,其他内网线路一般都使用双芯 LC 接口的多模光纤。囤积的各种光模块和衰减器:

网卡及适配器
目前电脑主板基本是没有自带光口的,因此需要买单独的网卡。万兆网卡最经典的选择就是 Intel 的 82599ES 了,大量互联网公司机房里使用的万兆网卡都是这型号的,稳定性啥的无需担心,模块兼容性也相对较好。82599ES 是芯片型号,因此有不同厂家的产品,同时有单口和双口两种型号可供选择。
然而 82599 也有翻车的时候,实际测试下来 82599 不能和威联通的 QSW-308-1C 交换机配合使用。威联通官网上有个兼容性列表,然而里面列出来的是模块不是网卡,并没有提到网卡也有兼容性问题。然而功夫不负有心人,我还是找到了一款能正常使用且相对便宜的网卡,这就是博通 Broadcom 57810S。
台式机可以装 PCIE 网卡来支持万兆网络,笔记本怎么办呢?除了极少数原生支持 2.5GbE 或者更高速率 RJ45 电口的笔记本外,只能通过 Type-C 口来外接适配器实现了。
绿联有一款 2.5GbE 的外置网卡,同时有 Type A 和 Type C 两种接口的版本,用下来体验还行,就是发热比较严重,不过也没感觉到对稳定性有影响。写这篇文章的时候发现绿联又出了一款 5GbE 的产品,同样是使用 RJ45 电口的,最重要的是,这两款产品的价格都比较亲民,感觉可以搞来试试。
至于 10GbE 的外置网卡,目前只发现了威联通的 QNA-T310G1S,这是一款 SFP+ 光口的外置网卡,至于价格嘛,当然是比较贵了,笔记本其实对 10GbE 没有太高需求,因此暂时没考虑入手。
线材
网线目前基本用 Cat 6 的网线就差不多了,也可以选择 Cat 7 的,价格差不了多少,至于 Cat 8 的嘛,哪时候可以搞一根来看看。其实严格来说并不存在 Cat X 的网线对应什么速率的关系,信号衰减程度和距离关系很大,如果就几米距离 Cat 5e 的网线一样可以达到万兆的水平。距离长了 Cat 7 的网线也是会有问题的,当然在等距离下,Cat 级别越高的网线肯定更好些喽。不过越好的网线也会越硬,如果要穿线的话就更困难了,这时候扁线的优势就体现出来了,而且扁线看起来也要高级那么一些呢。
至于光纤的选择,入户光纤没得选,就一条单模光纤;局域网内部使用的光纤一般用双芯多模光纤,与网线类似,光纤也是分等级的,从 OM1~OM5,不同等级的光纤外壳颜色不一样,比网线更好区分。一般来说,使用水蓝色的 OM3 光纤就可以了,详细信息可以看看这篇文章:
OM1、OM2、OM3、OM4和OM5多模光纤有什么区别?
与成品网线相对应的光纤叫做光纤跳线,就是两端都有 LC 或 SC 接口的光纤线,长这样的:

这种光纤使用起来十分稳定且方便,成品买来直接插上就好了,然而和网线一样的,由于接口体积比较大,长距离穿线时都是用没有两端接口的线的。网线的话买些水晶头和接线钳来自己练习下就可以搞定 RJ45 接口的安装了,光纤可就没这么简单了。
光纤一般是买尾纤来连接起来的,所谓的尾纤就是只有一端做好接口的光纤,两条尾纤接起来就是完整的光纤了。然而要怎么接呢?有两种方法,冷接和熔接。最初我以为自己可以搞定冷接的,买了一堆工具来尝试冷接,坑爹的是接是接起来了,然而不是一拉就断了,就是插入损耗太大简直没法用……
最终还是认清现实了,乖乖的去淘宝上找了同城提供光纤熔接服务的商家上门来进行光纤熔接。光纤熔接后需要一个熔接盒/熔接盘一类的东西来进行一些保护,这些可以自己去单独买,也可以请熔接的商家带一些来,最终成品的效果:

除了这种普通光纤外,还有一种很特殊的光纤——隐形透明光纤,这种光纤一般用于在室内拉明线时使用,不注意看基本看不到,十分美观。这种光纤都是单模光纤,没有多模光纤,因此对应的光模块也要选择单模模块。客厅交换机到工作室 PC 的连接我就使用了这种光纤。
两个 SFP+ 接口在短距离连接时更好的选择是使用 DAC 线而非光模块 + 光纤的形式。DAC 线实际上就是铜线,两端都是 SFP+ 接口,像网线那样直接插上去就可以用了,十分方便。DAC 线只能用于短距离连接,然而它的稳定性和兼容性比模块 + 光纤好太多了。

性能测试
来测试下万兆网络的性能吧,在软路由服务器上运行 iperf3 作为服务器端,PC 上运行 iperf3 客户端:
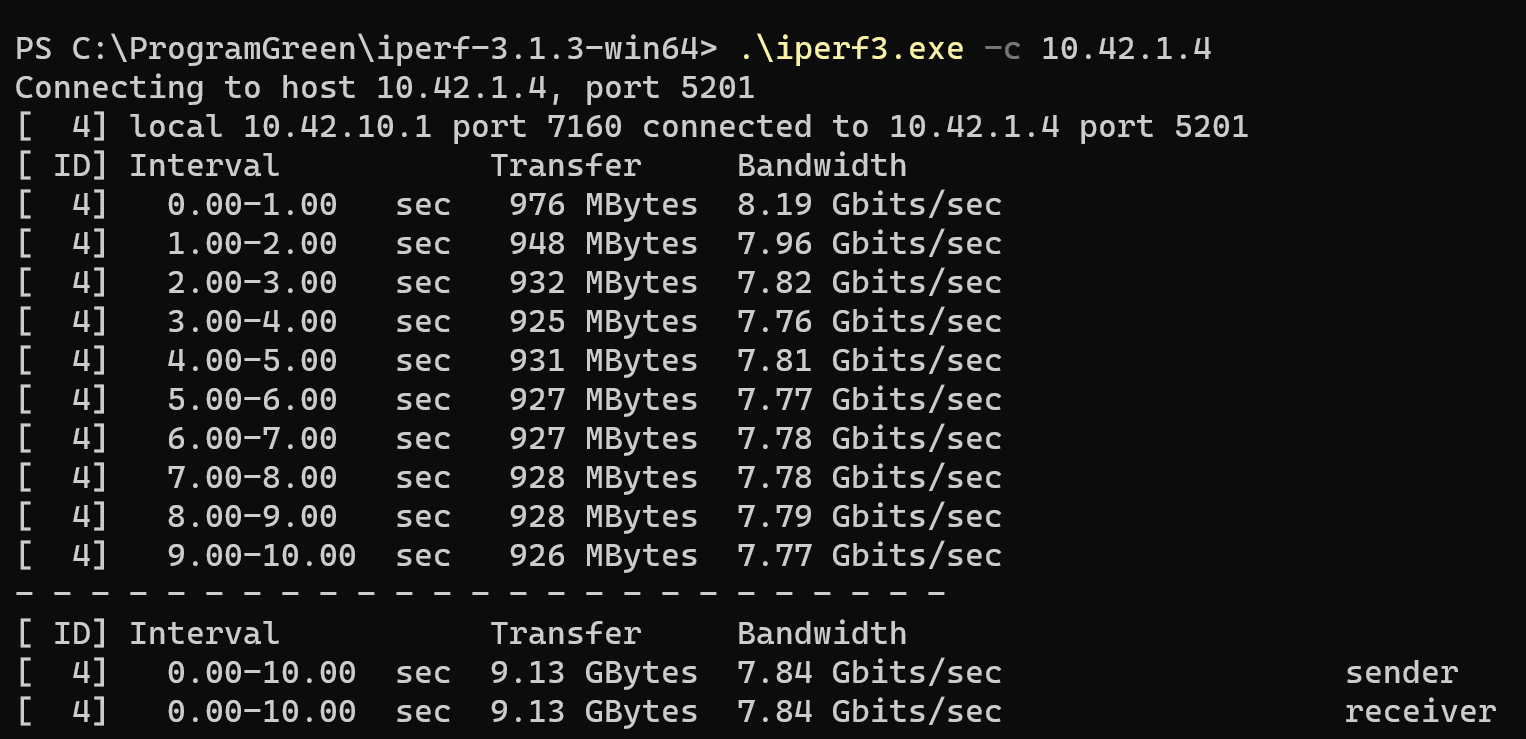
可以达到 8Gbps 的速度,已经比较满意了。
无线网络
由于家里墙体较多,因此选择了无线 AP 的方式来提供 WiFi 服务。AP 分为两种,带管理功能的 FAT 模式胖 AP 及单纯的接入点瘦 AP,有不少 AP 是二合一的,可以自行选择使用哪种模式。考虑到多个 AP 要能较为方便的进行统一管理,使用瘦 AP 模式 + 单独的 AC 控制器是最优选择。
从家居美观的角度来看,86 面板型 AP 无疑是一个很好的选择,一般是一个房间或相邻几个房间放一个。当然更严谨的做法是简单算算无线覆盖情况,以此来决定把面板放哪,这在装修阶段比较实用。TP-Link 提供了一款小工具来计算 WiFi 无线场强分布情况:
TP-LINK无线规划工具 V1.0.5
Mac 上有另一款类似工具,张大妈上已经有人安利了:
实用小软件 篇四:家庭无线布网好帮手,一张图让看清WIFI(内含下载)
86 面板型 AP 一般都是 PoE 供电的,常用做法是直接选择带 PoE 功能的交换机或 AC 控制器即可,然而为了选择带万兆 SFP+ 接口的交换机已经把范围缩小了很多,此类交换机基本都是没有 PoE 接口的。此时可以选择再买几个单独的 PoE 交换机来,先不说搞一堆交换机来不优雅的问题,这么做有个缺点,两个交换机之间只能通过单条网线进行串联,因此相当于多个 AP 接入点是共享了 1GbE 的带宽。虽然实际上这并不会对使用造成什么影响,然而总是觉得不爽啊。
于是去搞了一对一的 PoE 供电器来,即每路 AP 都是一条输入线一条输出线。此类模块单路的比较常见,然而家里面有 6 个 AP,买 6 个供电器来实在太丑陋了,所以当时找了好久,终于在闲鱼上发现了一款 4 路供电模块,就是上文机柜 PDU 电源图中电源上面那个东西。这东西现在在淘宝上都搜不到的,也算是捡到好货了。
至于 AP 面板的选择,这套无线是两年前搭建的,当时 WiFi 6 才刚出来没多久,因此支持 WiFi 6 的 86 型 AP 面板就没几款,基本没有选择,所以目前家里面用的是 TP-Link 的 XAP1800GI-PoE,这是款 AX1800 AP,两年多用下来稳定性还不错,也就整体重启过 1,2 次,属于可以接受的范畴。
现在有些速率更高的产品出来了,比如 XAP30000GI-PoE,XAP5400GI-PoE 等,其中 XAP30000GI-PoE 的性价比不错,如果是现在重新安装估计就选这一款了。当然了,已经装好的显然没有足够动力去把它换掉的,等将将来 WiFi 7 出来再看看有没有啥吸引我更换设备的点吧。
至于单独的 AC 管理器,选 TP 最便宜的 TL-AC100 就可以了。不过这里又遇到一个坑啊,当初从闲鱼上买了个二手的 TL-AC100 来,发现不能用,然后才发现同样的型号有不同的硬件版本号,老版本的不支持新的 AP……
这类 AP 都可以提供很多个 SSID 供接入的,目前使用了 3 个,一个主要自用的;一个供访客使用,打开了 AP 隔离开关;前两个都是 2.4G 5G 双频合一的,然而有些智能家居设备不支持双频合一,于是又单独搞了个纯 2.4G 的 SSID,专供各种智能设备使用。
AP 接入方案的优点自然就是信号覆盖好了,现在家里面卫生间角落也能保证有稳定的 2.4G 网络可用,实现了无死角全覆盖。然而这方案理完美还有不少距离的,最大的痛点就是移动过程中 AP 切换问题,自动切换当然是可以切换的,然而这一过程并不能做到完全无感。看视频这类应用因为有本地缓冲,基本没啥影响,但如果在使用着微信语音之类实时应用就会感到切换时会卡几秒……
据说 WiFi 7 已经在着手解决此问题了,方案是同时建立和多个 AP 的连接,而非现在这样断了一个连另一个,感觉可以期待下未来的实际表现。
至于 WiFi 速率问题,其实只有距离 AP 面板或路由器很近时才能发挥出 5G WiFi 的能力,高频信号衰减很快,基本穿一堵混凝土墙后无线速率就会大幅下降。来看看实际测试结果吧:

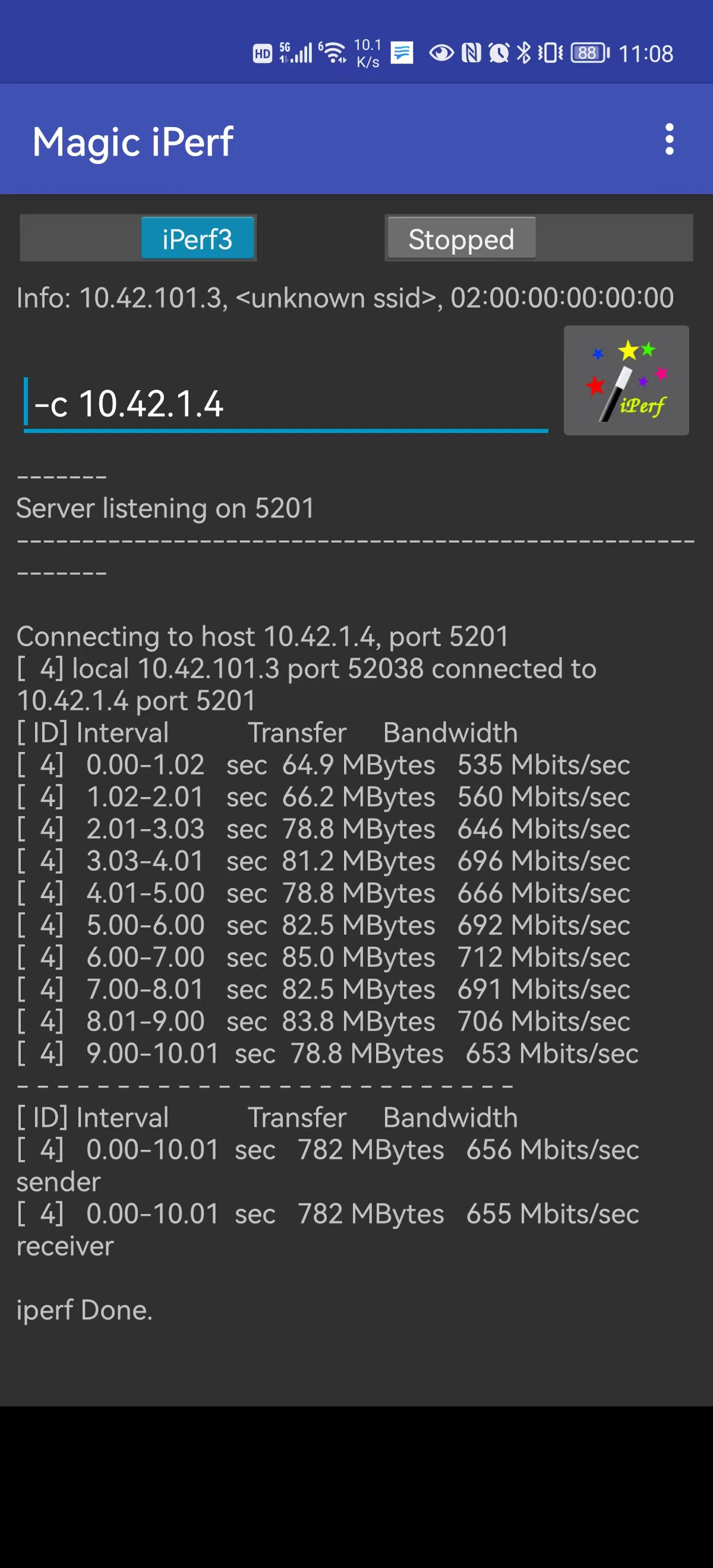

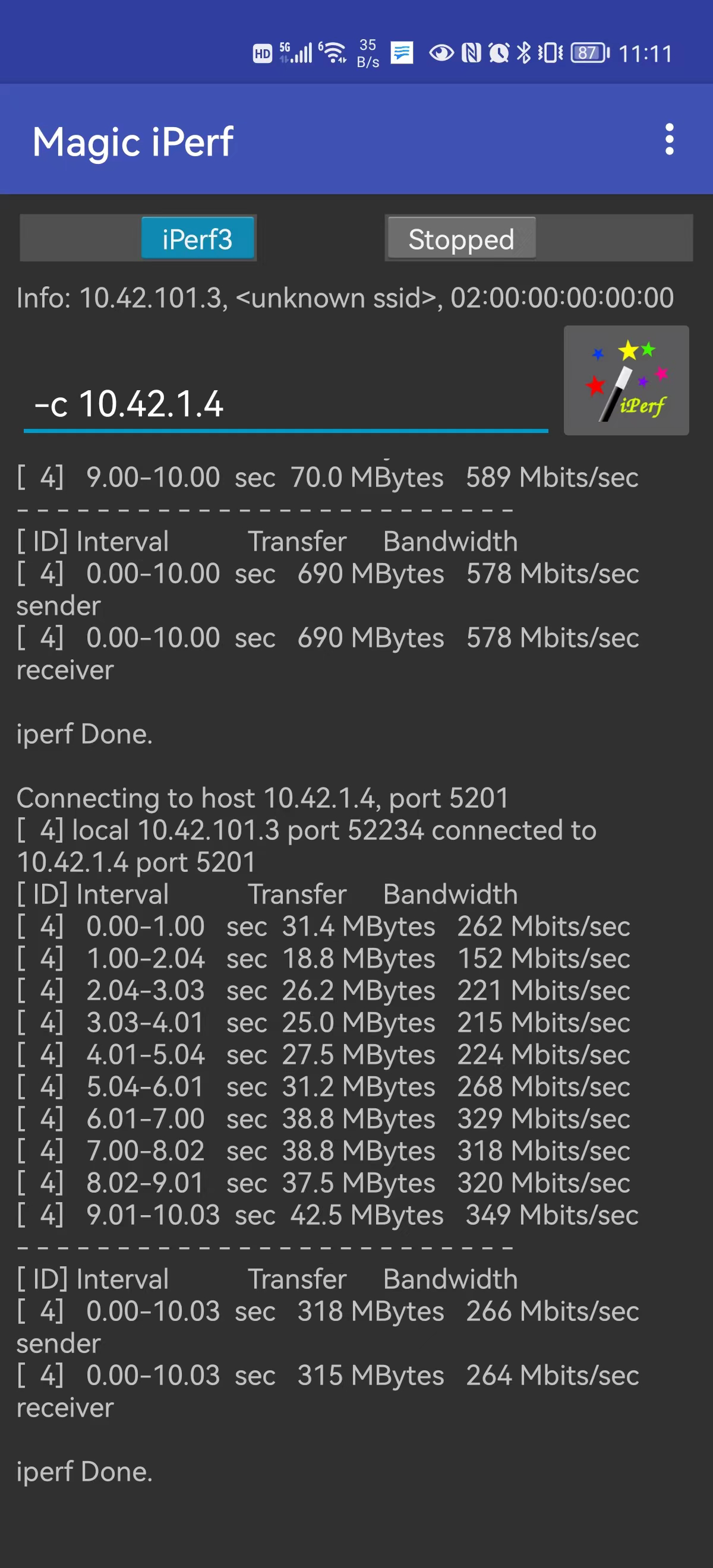
- 卫生间角落里,只有 2.4G 了,不过实测速率还行:


外网远程访问
家里面有这么多有趣的东西,在外面的时候当然会想着翻回家来看看喽~出于方便性及安全考虑,只把一个单点对外暴露,通过这个单点统一认证接入家庭内网后再访问其他服务。
最早的方案是用软路由实现的 L2TP 或 OpenVPN,然而此方案稳定性不佳,经常会连不上,折腾来折腾去都会有各种奇怪问题。再加上换了电信新的光猫后,DMZ,端口映射这些功能还一直不太正常……于是放弃了这条路,选择了使用蒲公英旁路路由方案,就是这货:

蒲公英 P5 最大的优点是,它是以旁路路由的形式工作的,可以很完美的接入现有网络架构中,没有附加多余功能,专注于远程组网。使用起来也很简单,Oray 提供了各平台的客户端,直接下载使用即可。一般情况下都可以打通 P2P 隧道,这样就是点对点通信了,不需要中转,带宽仅取决于两端网络情况。
不过蒲公英 P5 有个很奇葩的设计,免费版本只能接入 2 台终端设备,不够的话要额外购买服务,我想着要买就买吧,价格正常也可以接受,然后就看到奇葩东西了,要买的话一个终端 ¥78 一年,先不说这价格贵不贵,关键是,我要加第 3 个设备,不是按正常人类的想法,再买一个就好了,而是要把之前两个免费的也算上,一共买 3 个终端才行
算算价格,我每年要花 200 多的服务费,然而这设备本身才 200 多块钱,我为什么不再买一个?于是乎,就有了两个蒲公英 P5……
蒲公英 P5 目前只能算满足基本需求能用了,目前正准备升级这部分,搞一套飞塔 Fortinet 的 SDWAN 防火墙来。Fortinet 算是国际大厂了,大量中小型企业甚至是大型企业的硬件防火墙使用的都是 Fortinet 的产品,在 Gartner 的魔力象限中也遥遥领先。目前主推的桌面型无风扇设备是下面这三款:
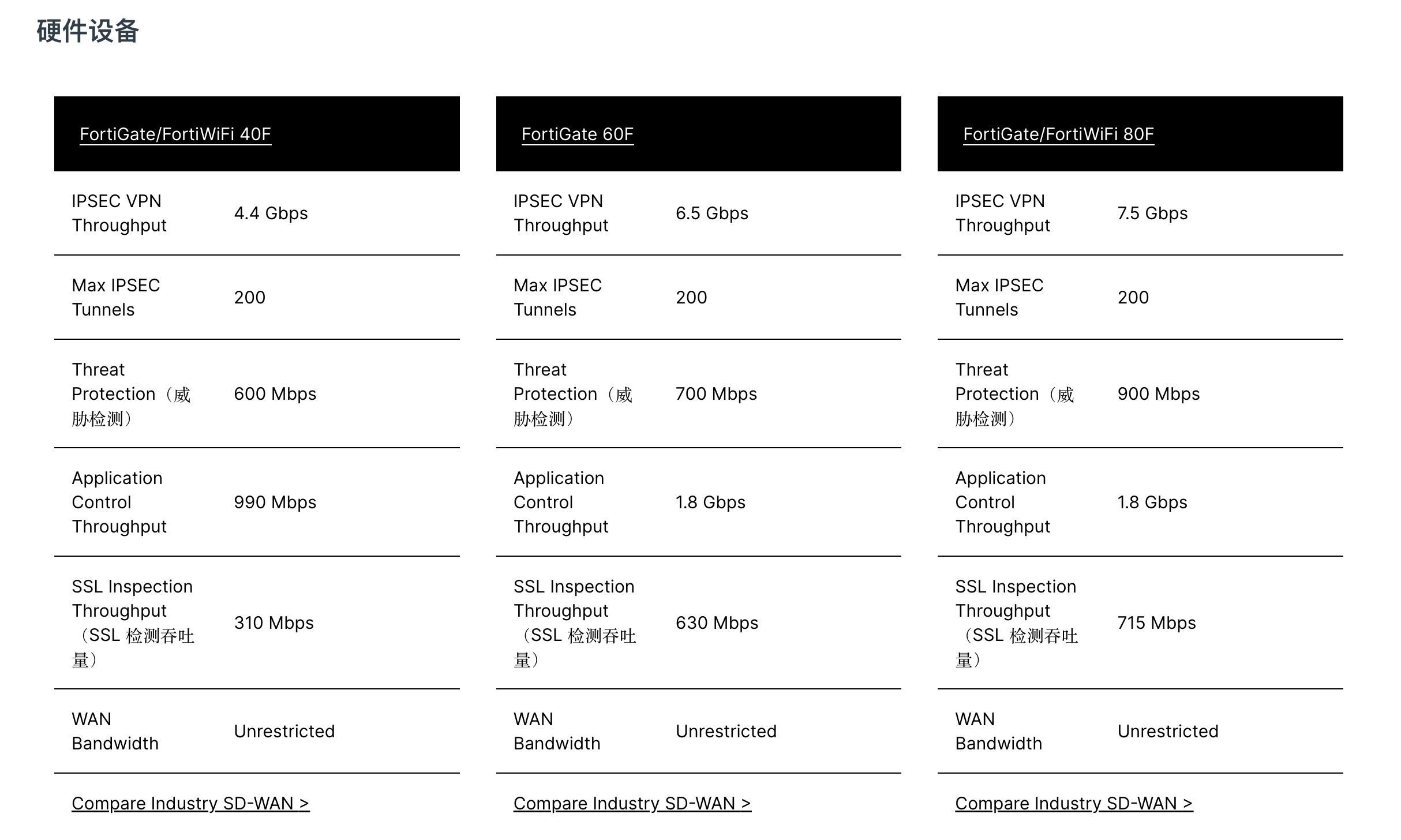
当然了,如此先进的企业级设备价格也是企业级的喽,全新机器基本都是 5000 以上的。这么贵的全新机器当然是买不起的,由于有大量企业在使用 Fortinet 的产品,自然想到去闲鱼上找一些二手设备来用用了。反正现在魔都也发不了快递,正好好好研究下选那个型号好。
软路由服务器
实际上这就是一台正常 PC 机,硬件上没有什么特别的,处理器是多年前的 AMD 1700,64G 内存,2 块 SATA SSD + 1 块 NVME,网卡就是前文提到的双口 82599,此外还有主板自己板载的 RJ45 口。
机器安装了 PVE 作为虚拟化平台,PVE 同时支持虚拟机和 LXC 容器,软路由使用的是虚拟机,其他的 LXC 容器居多。当然说到容器的话 Docker 的生态会更好些,因此也同时安装了 Docker,LXC 和 Docker 混合着使用,能用 LXC 的优先选 LXC,LXC 没有的用 Docker。
软路由的选择上也折腾过很多,目前用的是 HomeLede 这个基于 OpenWRT 的定制版本:
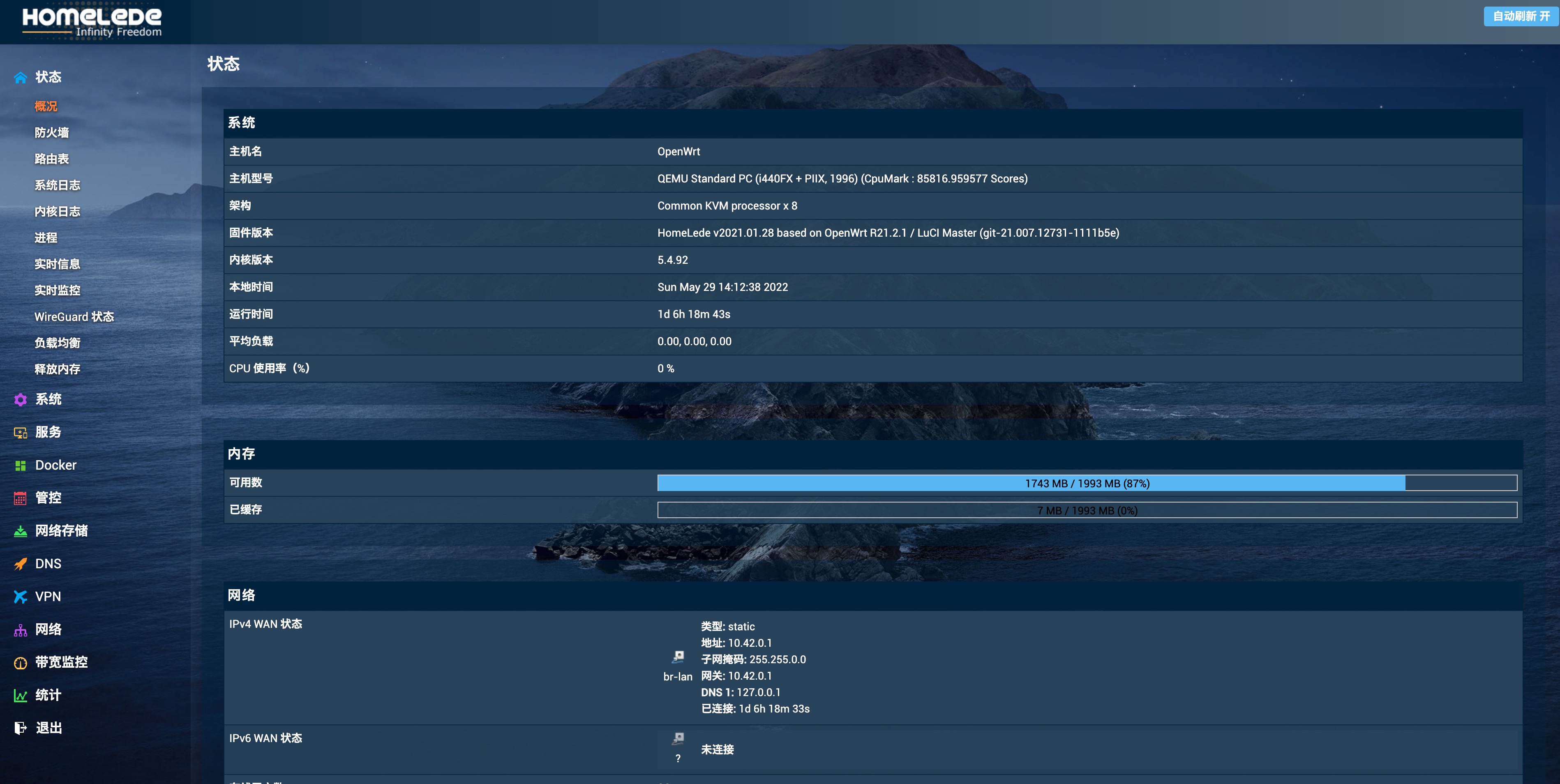
软路由的稳定性上还是有所欠缺,基本每个月都要重启一次系统才行,不过好在一般重启了也就都正常了。
这台机器当然不仅仅是作为软路由来使用的,只当软路由也太浪费了一些,上面还运行着各种不同服务:
- Ubuntu 20.04,用于当作日常开发机使用,VS Code 啥的都是用远程模式连过去工作的;
- Gogs,比 Gitlab 更轻量级的私有 Git 仓库,简单好用;
- MySQL,基础数据库服务;
- InfluxDB,时序数据库服务,用于保存智能家居等的监控数据;
- Home Assistant,开源智能家居控制中心;
- Nginx + PHP & Node.js,用于搭建家庭小网站;
- 。。。。。。
NAS 存储
家庭中心化存储的核心自然就是 NAS 啦,目前家里面有两台 NAS,一台用蜗牛星际搭的黑群晖,另一台是威联通的 TS-532X。来一张合影:

蜗牛星际就不多说了,懂的都懂,多年前垃圾佬最爱的东西,几百块钱就有 NAS 了。然而垃圾毕竟是垃圾,使用起来问题不少,最严重的问题是,蜗牛星际机器的散热太差了,装满 4 块硬盘同时工作的时候,经常触发超温报警,甚至是直接过热关机因此目前重要的资料都没放在这个 NAS 上,也正在想办法改进下散热问题……
威联通的 TS-532X 还是很好用的,可以装 3 块 3.5 寸盘 + 2 块 2.5 寸盘,一般那两块 2.5 寸盘都是放 SSD 的,QNAP 有 QTier 自动分层技术,可以自动把经常使用的数据移到 SSD 上。
RAID 的配置上,3 块 HDD 使用 RAID 0,2 块 SSD 使用 RAID 1。至于怎么解决 RAID 0 数据安全性问题呢,当然是备份喽,其实 RAID 并不是解决数据安全性良好的方案,更大的意义是提供高可用和高性能。
数据备份
QNAP 的数据备份功能做得还是不错的,用的是 HBS3 这款软件,前几个月刚刚添加了百度网盘支持,因此目前备份比较好的选择是百度网盘和阿里的 OSS 对象存储。两个我都试用了一下,HBS3 对阿里 OSS 的支持似乎有些 Bug,太大的单体文件(比如几十 GB 的文件)上传会失败,给他们提了工单不知道目前解决了么。因此目前备份选择的是百度网盘。在初始几次全量备份的时候失败率比较高,会有些文件上传失败,不过不用管它,多来几次,后面的定期增量备份数据量不大基本都是全部成功的。
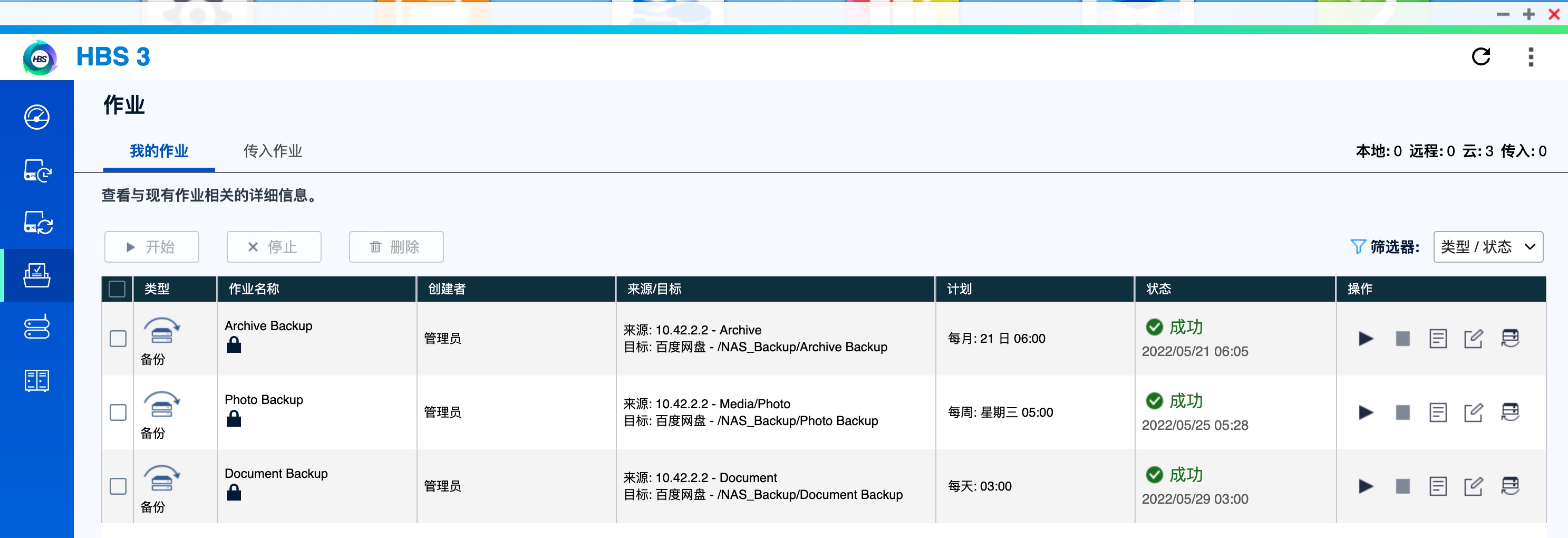
QNAP 提供了数据加密功能,上传上去的数据可以都预先加密一次,因此无需过多担心隐私安全问题。如果想要从百度网盘里下载个别文件怎么解密呢,此时可以使用 QENC Decrypter 工具:

硬盘选择
再来说下硬盘选择问题吧,大部分 NAS 玩家都喜欢使用希捷酷狼,西数红盘等,其实这里还有一个性价比更高的选择,那就是选企业级硬盘。企业级硬盘在可靠性,性能等方面是完全可以满足要求的,质保也要更长(一般都是 5 年),单位 GB 价格其实还要更低一些,唯一的缺陷是企业级盘不太考虑噪音,功耗等问题。威联通自己的推荐磁盘列表里就有不少希捷银河系列企业盘。目前我用的是希捷的 ST8000NM000A & ST3000NM0033,分别是 8T 和 3T 的盘。当前性价比比较高的是 16T 的 ST16000NM000J:
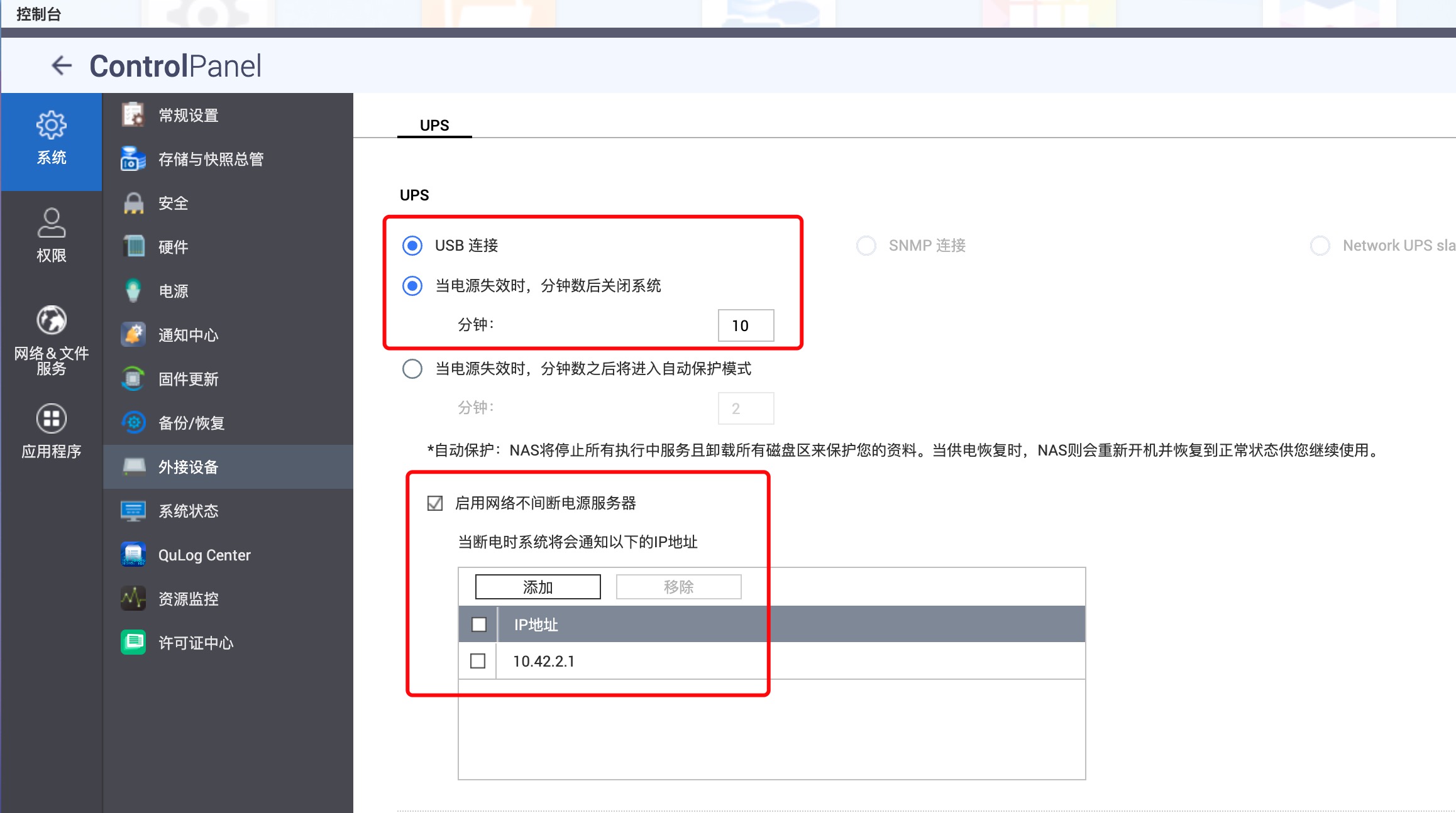
UPS 电源
最后再来说下供电问题吧,为了避免突然断电对硬盘造成不可逆损坏,一般 NAS 前都会加 UPS 不间断电源。为 NAS 设计的 UPS 有个 USB 输出口,发生断电后会通知 NAS 关机。不过这个 USB 口只有一个,只能连接到一台 NAS 上,那有多台 NAS 怎么办呢?让连接 USB 接口的 NAS 通过网络向其他 NAS 进行广播就好了。
性能测试
从 NAS 中拷贝大文件至 PC:
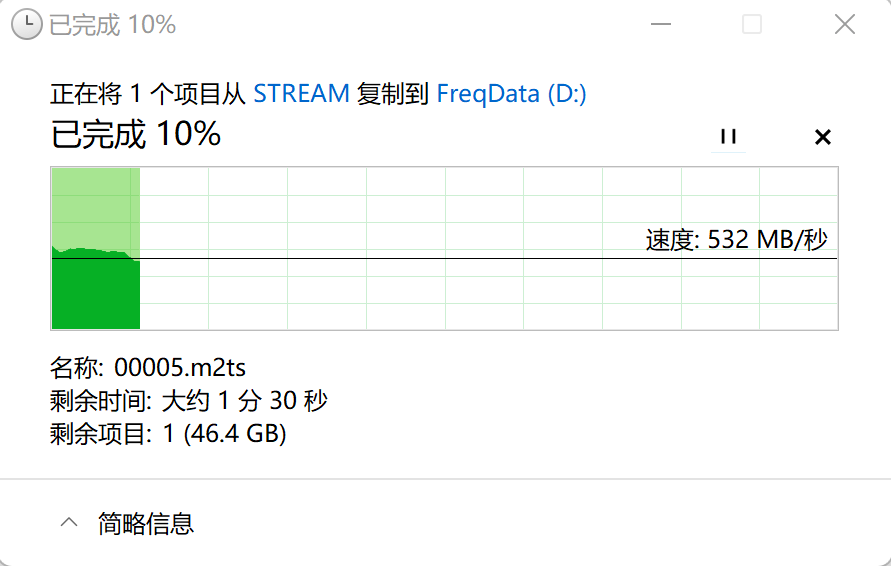
这个速度在维持了一段时间后会有所降低,此时的性能瓶颈是在 NAS 的 HDD 读取速度上的,要是买个盘更多的 NAS 或者直接用 SSD 那就可以充分发挥出万兆网络的优势了。
]]>