正则表达式(Regular Expression,在代码中常简写为regex、regexp或RE)是一个字符串,此字符串用于描述、匹配一系列符合某个句法规则的字符串。
正则表达式引擎是一种可以处理正则表达式的软件。通常,引擎是更大的应用程序的一部分。在软件世界,不同的正则表达式引擎并不完全互相兼容。
正则表达式引擎缺省是大小写敏感的。
此处总结下常用的正则表达式规则。
特殊字符
有12个字符被保留作特殊用途,它们是:[ ] \ ^ $ . | ? * + ( )
如果要在正则表达式中将这些字符用作文本字符,需要用反斜杠\对其进行转义。
在编程语言中,一些特殊的字符会先被编译器处理,然后再传递给正则引擎。因此为了匹配"C:\temp",要用正则表达式"C:\\temp"。而在C++中,正则表达式则变成了"C:\\\\temp"。
重复
不加数量限定则代表出现且仅出现一次。
| 模式 | 含义 |
|---|---|
* |
重复零次或更多次(任意次) |
+ |
重复一次或更多次(至少一次) |
? |
重复零次或一次(至多一次) |
{n} |
重复n次 |
{n,} |
重复n次或更多次(至少n次) |
{n,m} |
重复n到m次 |
* + ? 的重复具有贪婪性,即试图匹配尽可能长的字符串。如需要非贪婪模式,即匹配尽可能短的字符串,在任意一个重复限制符后加上一个?,即:*? +? ?? {n}? {n,}? {n,m}?
获取文本
使用**()。(exp)**匹配exp,并将匹配到的文本缓存到自动命名的组里。命名规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。要获得之前匹配的文本,在表达式中使用”"加上组号的形式,如”\1”。
在VS替换文本操作中,替换为的文本中如需包含原文本,使用”$”加上组号的形式,如”$1”。
字符集
用[]组合表示一个匹配集合,如[abc],字符集中不区分顺序。可以使用连字符-定义一个字符范围作为字符集。
在左方括号[后面紧跟一个尖括号^,将会对字符集取反,结果是字符集将匹配任何不在方括号中的字符(包括\n),很重要的一点是,取反字符集必须要匹配一个字符。
在字符集中只有4个字符具有特殊含义,它们是:] \ ^ -
]代表字符集定义的结束;\代表转义;^代表取反;-代表范围定义。其他常见的特殊字符在字符集定义内部都是正常字符,不需要转义。例如,要搜索星号*或加号+,可以用[+*]。当然,如果对那些通常的特殊字符进行转义,得到的正则表达式一样正确,但是这会降低可读性。
如果用?*+操作符来重复一个字符集,将会重复整个字符集,而不仅是它匹配的那个字符。
选择匹配
即逻辑或操作,用|把不同的规则分隔开。通常使用(?:exp1|exp2)的形式。(?:)代表匹配但不获取匹配文本。
位置锚定
| 模式 | 含义 |
|---|---|
^ |
匹配一行字符串第一个字符前的位置,即行首 |
$ |
匹配字符串中最后一个字符的后面的位置,即行尾 |
\b |
匹配一个单词边界,也就是指单词和空格间的位置。 |
常用字符集
| 模式 | 含义 |
|---|---|
. |
匹配任何单个字符(换行符\n除外) |
\d |
匹配任何数字字符 |
\s |
匹配任何空白字符,等价于[ \f\n\r\t\v] |
\w |
匹配字母或数字或下划线或汉字 |
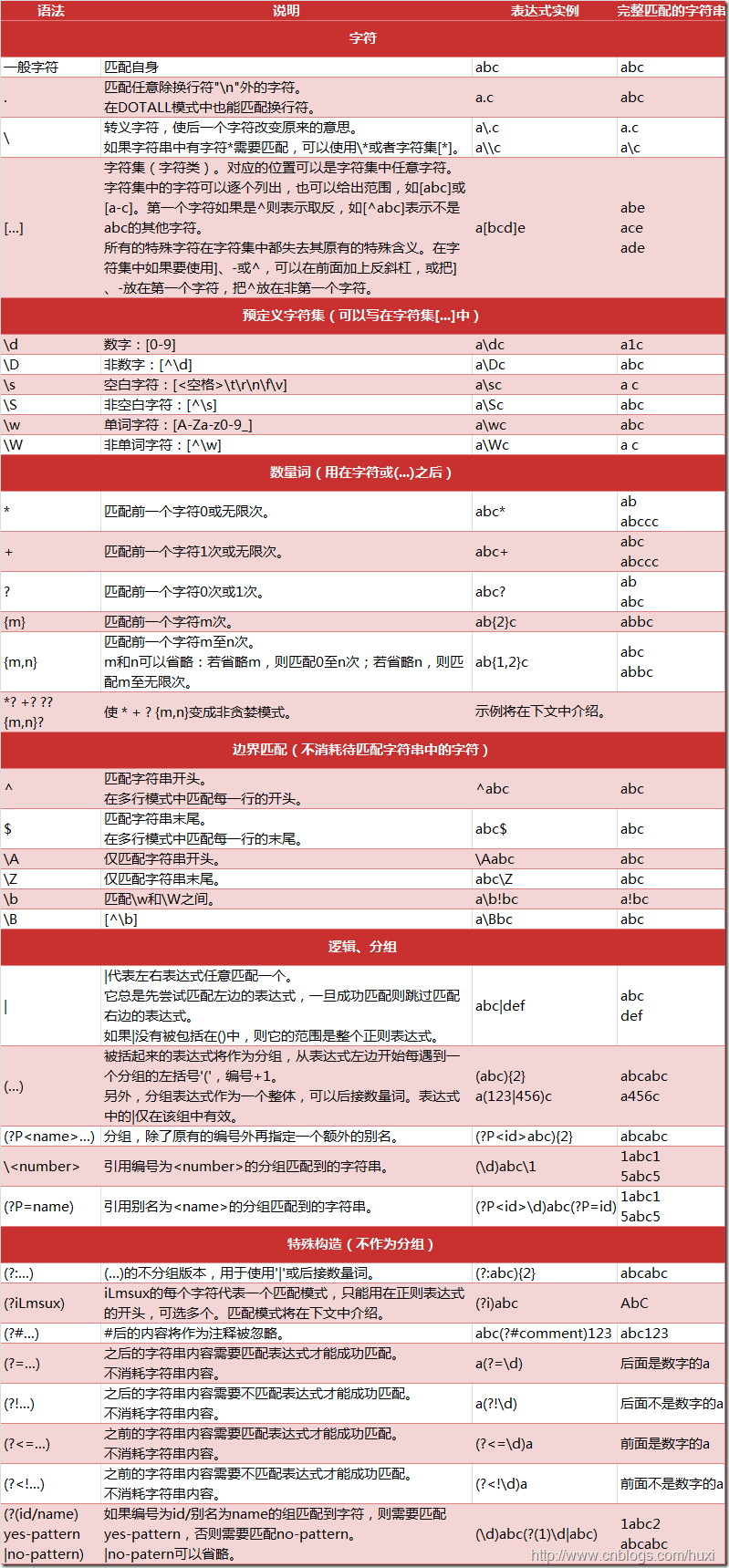
最后附上一张相对完整的正则表达式规则以供参考: