结构体成员在内存中并不是紧凑排列的,这就是所谓的结构体内存边界对齐问题,默认情况下会按照其自然边界对齐,本文将具体研究下这一问题。
先来看一个简单的小程序:
1 |
|
使用GCC编译运行,输出结果为:
1 | Struct size is : 12 |
从结果中可以很明显的看到,结构体成员在内存中并不是紧凑排列的,这就是所谓的内存边界对齐问题。进行结构体内存边界对齐是为了让CPU读取数据时效率达到最大化,关于这个问题此处不深入研究,仅引用一个网上的解释:
字,双字,和四字在自然边界上不需要在内存中对齐。(对字,双字,和四字来说,自然边界分别是偶数地址,可以被4整除的地址,和可以被8整除的地址。)
无论如何,为了提高程序的性能,数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;然而,对齐的内存访问仅需要一次访问。
一个字或双字操作数跨越了4字节边界,或者一个四字操作数跨越了8字节边界,被认为是未对齐的,从而需要两次总线周期来访问内存。一个字起始地址是奇数但却没有跨越字边界被认为是对齐的,能够在一个总线周期中被访问。
某些操作双四字的指令需要内存操作数在自然边界上对齐。如果操作数没有对齐,这些指令将会产生一个通用保护异常(#GP)。双四字的自然边界是能够被16 整除的地址。其他的操作双四字的指令允许未对齐的访问(不会产生通用保护异常),然而,需要额外的内存总线周期来访问内存中未对齐的数据。
下面主要分析一下编译器是如何处理结构体内存边界对齐问题的。
自然边界对齐
如果不手动指定对齐方式,就按照自然边界对齐原则进行对齐。
所谓自然边界,对于8bit数据来说,任何地址都是其自然边界;对于16bit数据来说,偶数地址是其自然边界(即最低位地址为0);对于32bit数据来说,能被4整除的地址是其自然边界(即最低两位地址为0);对于64bit数据来说,能被8整除的地址是其自然边界(即最低3位地址为0)。
结构体按照自然边界对齐原则进行对齐即是指:
- 结构体中的每个成员都存放在其自然边界上;
- 各个成员严格按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构体的地址相同;
- 结构体整体的对齐方式与其成员中长度最长那个元素相同;
- 为满足以上要求,在成员间和结构体最后可使用空字节进行填充。
根据以上原则就很好理解默认对齐方式了,下面给出几种结构体声明方式及其对应的内存分配情况图。图中每一个单元格代表一字节数据,灰色部分代表不属于此结构体的部分。
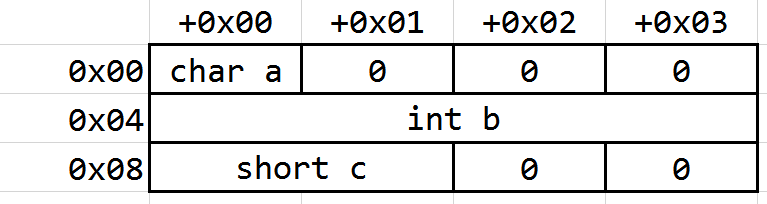
Case 1
1 | struct |
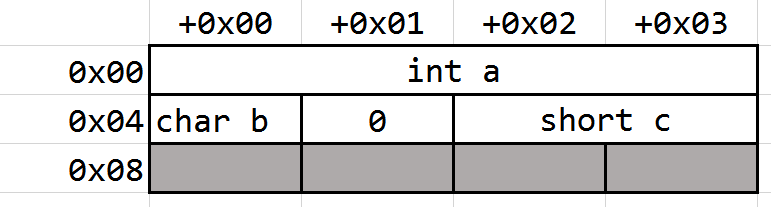
Case 2
1 | struct |
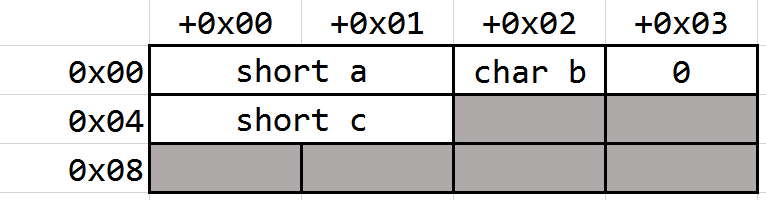
Case 3
1 | struct |
Case 4
1 | struct |

指定边界对齐
可使用一些编译器预处理指令来手动指定对齐方式,不同的编译器有不同的预处理指令,此处仅简要总结下GCC中的预处理指令。
#pragma pack(n)
其中n必须为2的若干次幂,如1,2,4,8,16等;若不指定n,相当于恢复默认的自然边界对齐方式。这个指令的效果是:按照#pragma pack指定的数值和这个数据成员自身长度中比较小的值来对齐。也就是说,当#pragma pack的值等于或超过所有数据成员长度的时候,这个值的大小将不产生任何效果,也就是说,这条指令仅可用于减小间隙。
用自然边界对齐中的Case 1为例,使用#pragma pack(1)强制对齐至1字节地址处:
1 |
|
程序输入为:
1 | Struct size is : 7 |
内存分配情况如下所示: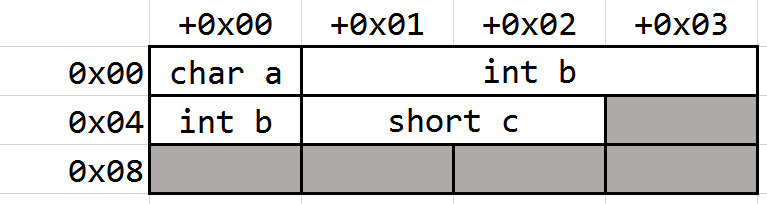
__attribute((aligned(n)))
同样,n需要为2的若干次幂,这条指令仅可以用于增加间隙。
用自然边界对齐中的Case 2为例,使用__attribute((aligned(4)))将每个成员都强制对齐至4字节地址处:
1 | struct |
程序输出为:
1 | Struct size is : 12 |
内存分配情况如下图: